Diffusion9-流视角
流视角
参考文献
Papers
Score-Based Generative Modeling Through Stochastic Differential Equations
A stochastic estimator of the trace of the influence matrix for Laplacian smoothing splines
Flow Straight and Fast- Learning to Generate and Transfer Data with Rectified Flow
Blogs
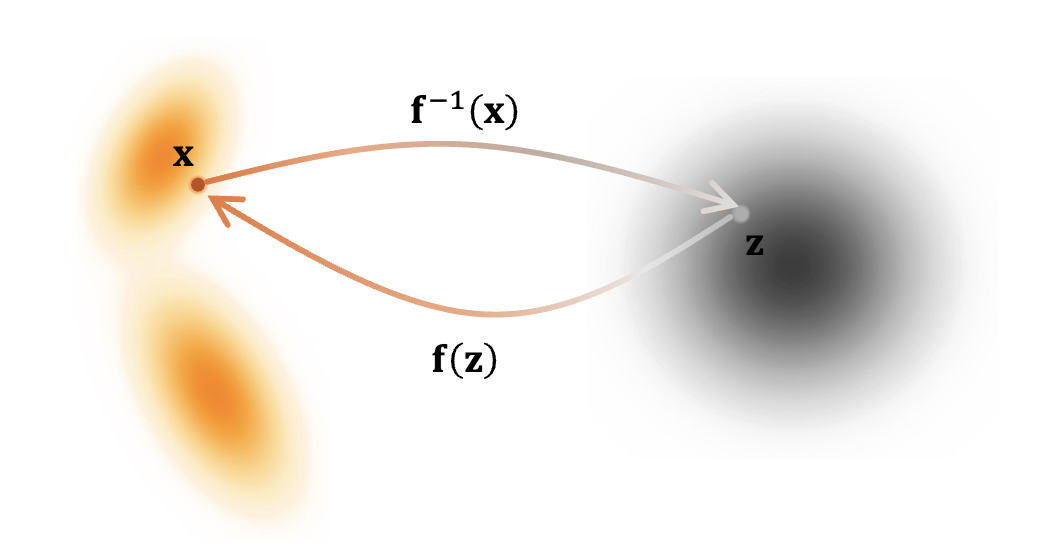
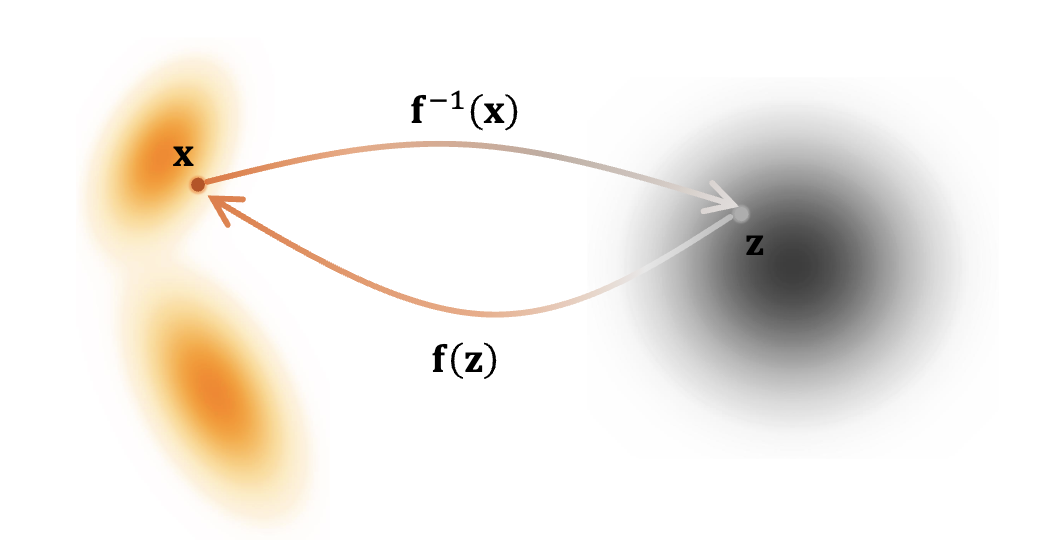
给定一个可逆变换
在
流模型
归一化流
基本定义
映射定义为:
其中
模型的对数似然
训练目标
参数
直接计算
计算瓶颈:雅可比矩阵

为了平衡表达能力和计算效率,采用一系列
变换链如下:
密度推导如下:
高效计算雅可比矩阵的单层结构例子
平面流
平面流应用一种简单的变换:
残差流
残差流将变换
对于任意方阵
矩阵
如果
所以:
雅可比矩阵的对数行列式可使用上述结论简化并展开为迹:
迹估计量(Hutchinson 估计量)
我们想要计算一个矩阵
对于任何方阵
定理:
常见的随机向量
- Rademacher 分布: 每个分量
独立且服从 - 标准高斯分布:
根据 Hutchinson 估计量,我们有:
定义向量序列
通过有限差分:
最后使用蒙特卡洛采样来近似期望:
设:
- 计算
次 矩阵向量积 - 计算一次
的复杂度 ,通常最快可以达到 - 采样的次数
总复杂度约为
采样与推断
采样: 抽取
推断: 直接正向计算即可
连续归一化流(神经微分方程)
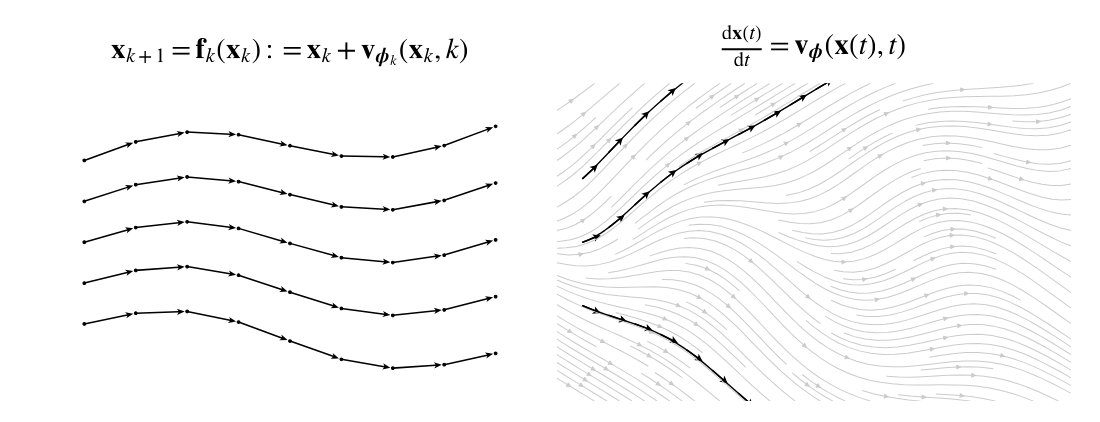
从残差流的视角,每一层可以表示为以下形式:
其中
直观上,这个残差表述可以连续化为:
这就是神经微分方程的框架,也称为连续归一化流
其中:
是时间 时的状态 是一个由 参数化的神经网络,代表神经向量场
训练目标
从初始条件
通过学习神经向量场
根据连续性方程:
展开右侧的散度项:
现在考虑一个满足微分方程的轨迹
沿这条轨迹
将
所以:
因此,给定先验
训练过程
训练遵循极大似然估计框架:
为了计算数据点
在高斯分布中采样得到
为了高效计算
散度使用随机迹估计量高效地进行估计
采样过程
- 从先验分布中抽取潜在变量
- 将
作为初始条件,向前积分ODE:
终止状态
流匹配
得分SDE与NF提供一种视角:
学习一种连续时间流,这种流能够将先验样本
流匹配框架尝试将其泛化为学习两个任意固定端点分布之间的流:
- 一个源分布
- 一个目标分布
那么,我们的目标就是,学习一个随时间发生变化的向量场
当
从得分SDE获得启发
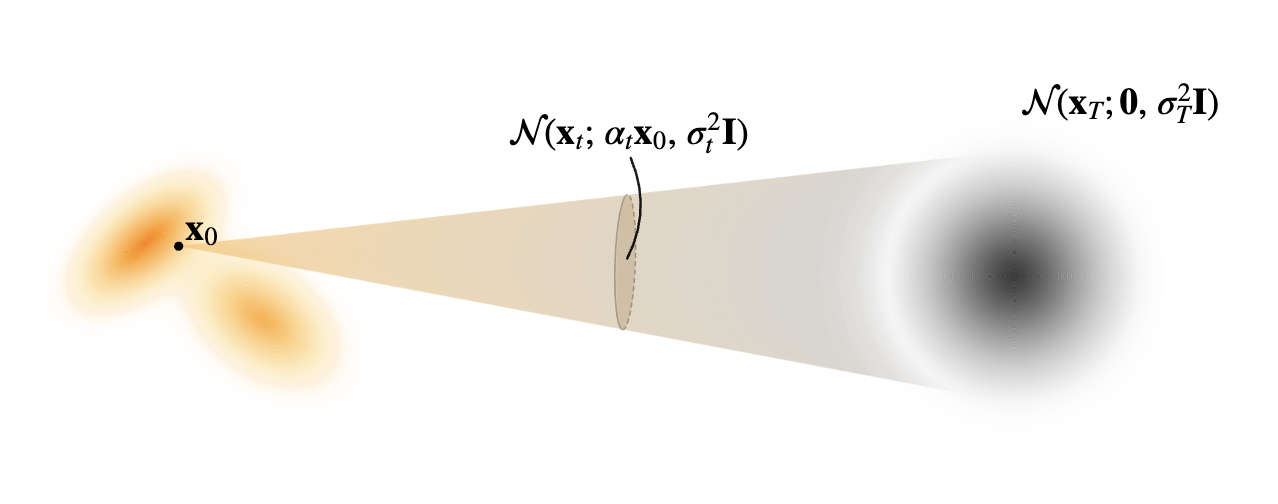
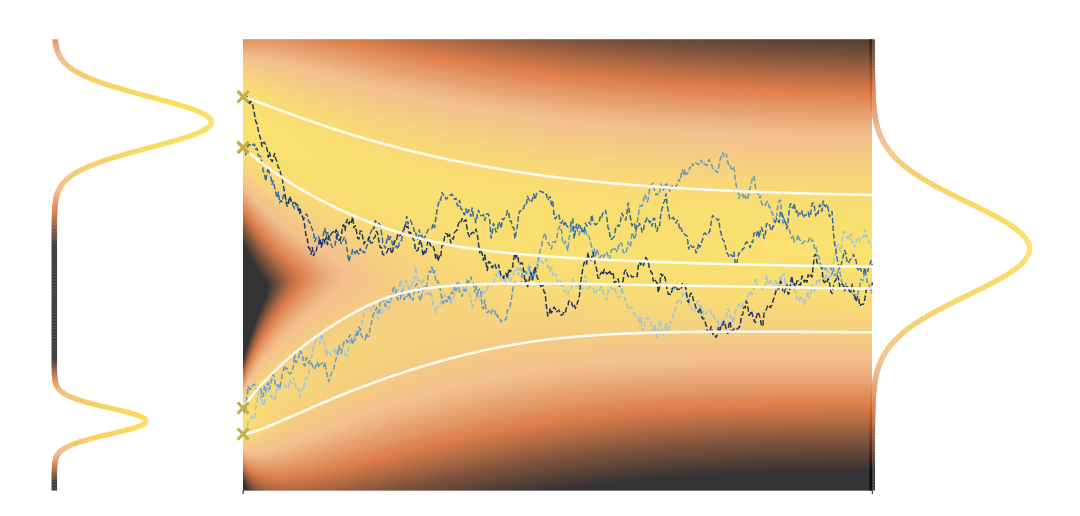
条件路径与边缘密度
通过扩散模型,指定了一个连续时间密度族
条件路径被定义为:
边缘密度被定义为:
速度场
边缘密度
由此同样定义了通过PF-ODE的确定性粒子流:
由福克-普朗克方程,可以保证,该常微分方程将初始随机变量

且
学习
利用神经网络去学习分数,从而逼近速度场:
由于边际得分难以获取,我们利用条件分布来定义速度:
由全概率公式,边际得分和条件分布有如下关系:
从而训练目标可以改变为:
从而最小化器可以满足为:
潜在规则:福克-普朗克方程
边际密度
由此确保PF-ODE给出的密度和前向SDE的边缘密度相匹配
PF-ODE的流映射定义为:
由福克-普朗克方程可以保证:
特别地:
流匹配框架
FM框架可以视为对于上述PF-ODE的扩展,FM框架将直接学习连续流,从而直接在两个任意分布,
条件路径和边缘密度
考虑任意源概率分布
FM 隐式地定义了一个连续的中间密度族
边缘密度
关于
的选取需满足 的边界条件 - 条件分布
应具有易处理的闭式表达式 的常见选择包括: - 双边条件:
, 这样的话,FM能够定义任意分布之间的传输 - 单边条件化:
或 ,当源分布为高斯分布时,能够恢复扩散下的场景
- 双边条件:
速度场
在标准扩散模型或高斯 FM 中,中间密度
然而对于通用FM来说,我们需要重头回顾这个过程:
我们目标是找到一个速度场
在每个时间点
任何满足上述式子的速度场
因此,求解常微分方程可实现从
直观地,设
均是该方程的解,也就是说,通用的连续性方程有无限个解,FM寻求的只是一个特定的速度场
通过条件策略进行学习
FM的学习目标一定是希望用一个神经网络
这被称为
但是,同样地,最优速度
从这个式子,我们可以作出两点要求:
- 从条件概率路径
采样应该是直接的 - 作为回归目标的条件速度
,必须具有简单的闭式表达式
我们需要对条件速度场进行边缘化去恢复边缘速度,由连续性方程得到:
根据全概率公式:
去除无散度项可以得到:
因此可以定义:
将其简写为:
最小化器
所以说,如果想要将通用的FM框架在具体的应用场景下进行特化,
流匹配中的参数设计
灵感来源:从高斯分布到高斯分布的设计
当源分布和目标分布
端点分布为:
我们需要设计一系列
对于
对于
代入得:
根据这个,我们希望推得速度场,对于具有初始条件
由于
对上式求导可以得到:
解
将其带入可以得到:
我们发现,在流优先的情况下,速度可以由以下范式完成构造:
此时,速度可以被唯一构造,若是给定密度路径
条件概率路径优先构造
我们旨在首先构造一个条件密度路径
首先有边界条件:
双边条件
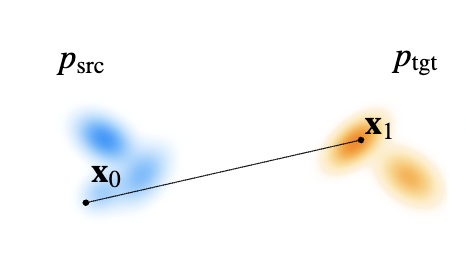
考虑定义在
选择条件路径:
其中
在确定性情况下
描述从
此时条件速度为:
CFM损失为:
此时的最优速度场为:
单边条件
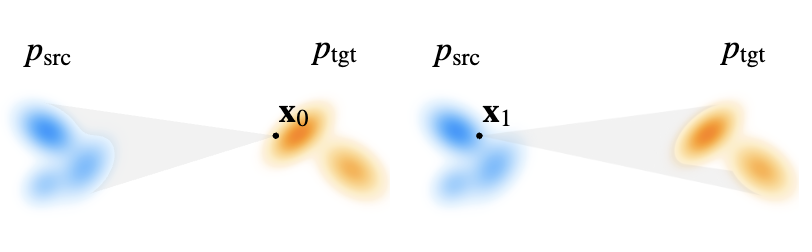
考虑标准的扩散模型的生成设置:
取
其中
对
由上述公式推导出条件速度
CFM损失为:
最小化器为:
对于配对样本
因此,单边损失会回归到给定
因此,单边和双边 CFM 目标函数具有相同的最小值点
高斯流匹配
若
此情景下,高斯流匹配可以被解释为一个等价的扩散模型,目标是预测速度,其损失函数简单易用,并且已经在大规模的场景下被验证为有竞争力的性能
| 属性 | VE(扩散 → FM) | VP(扩散 → FM) | FM / RF(线性) | Trig.(三角路径) |
|---|---|---|---|---|
条件流优先构造
直接定义一个随时间变化的映射函数
这样有两个优势:
- 训练目标(速度场
)可以直接通过对映射函数求导得到,不需要模拟 - 几何兼容:在球体、流形等复杂空间上,可以直接利用最短路径来定义这种映射
对于这个映射,建立一个仿射变换的模版来构造:
在
条件路径的诱导
给定条件
路径定义为:
实际当中:
如果
条件速度的诱导
根据ODE定义:
代入定义:
同样地:
代入后得到闭式解:
单向条件化(
令
有边界约束:
(回到起点噪声) (到达目标数据)
利用公式
在训练时,实际上是采样了一对
双向条件化 (
当我们同时固定起点
因为轨迹是确定的
无条件高斯路径
若
| 轴 | 条件概率-路径优先 | 条件流-优先 |
|---|---|---|
| 给定 | 条件密度路径 |
条件流映射 |
| 获取速度 | 对每个 |
沿路径(对每个 |
| 不唯一性 | 若 |
给定 |
| 可逆情形 | — | 若 |
| 闭式表达 | 当 |
当 |
| 对每个 |
给定 |
|
| 可实现性 | 必须验证构造的 |
构造天然保证成立: |
| 匹配 |
混合条件: |
设定 |
| 优选场景 | 扩散型构造;通过条件高斯分布实现对 |
通过映射施加强结构先验 |
流匹配的具体例子:ReFlow
当我们选择
根据通用公式:
求导得到:
训练目标变为:
这种独立抽样的条件流匹配是独立抽样的,耦合方式为:
问题是两个端点之间毫无关联,所以虽然这种方式采样简单,但是会导致路径成锯齿状,神经网络很难学习到这种形式的向量场
那么,利用一个预训练的扩散模型
从
通过积分得到的终点
从而,有校正操作:
- 输入:参考路径
(e.g., ) - 预训练扩散模型:在选定的路径上拟合
: - 校正:采样
,并求解 ODE: - 从而获得
及其完整的轨迹 - 输出:依赖配对
和完整轨迹
有效原因:
设
- 源边缘保持,即起始的噪声分布不受影响:
- 时间
时的分布是 通过流映射的前推
如果预训练模型
这种修正是用平滑的、教师引导的轨迹替代了噪声干扰的独立配对
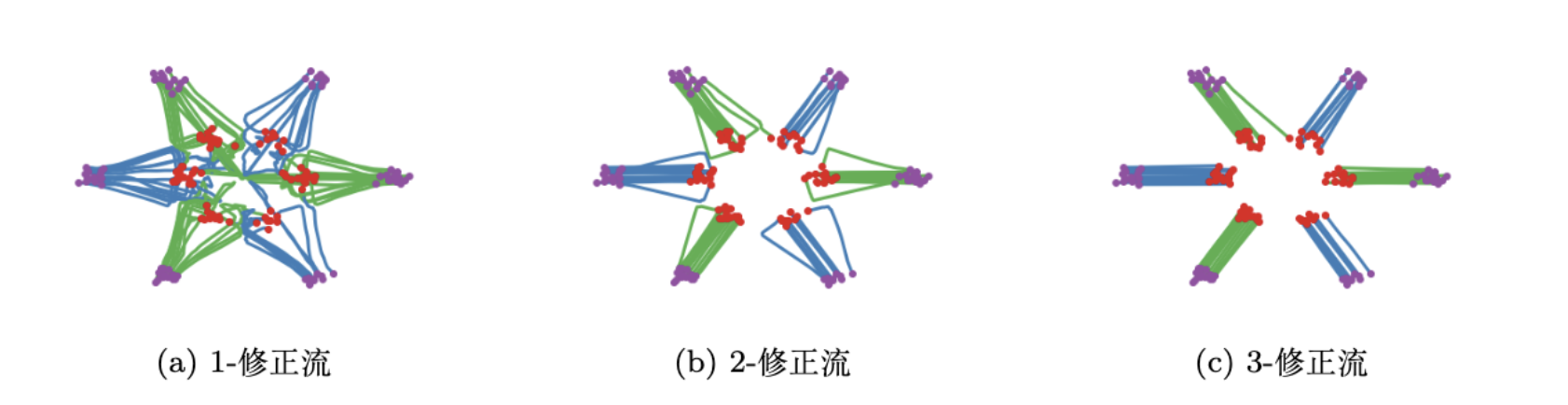
Rectify进行递归修正
Reflow:反复应用 Rectify 来更新耦合,使得后续的流更易于积分,也就是这个传输路径更加接近于两个分布之间的直线
初始状态
此时,
Reflow过程之重拟合
从当前耦合中训练一个新的速度场
其中:
轨迹设定为直线插值:
Reflow过程之新耦合
利用新学到的速度场,从新的噪声样本
更新耦合关系:
Rethinking Reflow
重复应用 Rectify 算子,生成一系列逐步优化的匹配关系:
Reflow不再是死板的随机配对,而是寻找一种最优的、冲突最少的传输方案
这种替换能诱导出更低曲率的路径,通过不断迭代,逐步降低路径曲率,从而显著提升数值稳定性和样本与噪声之间的对齐性
这种稳定的传输路径使得训练更加简单,同时因为轨迹变直,在推理时使用极简单的求解器(如 1 步欧拉法)也能获得极高的生成质量
该框架不仅适用于正则线性路径,也适用于一般仿射形式
Reflow的性质
Reflow 不会增加运输成本
令
Reflow 使路径变直
定义路径
对于修正路径