Reinforcement Learning3-GRPO
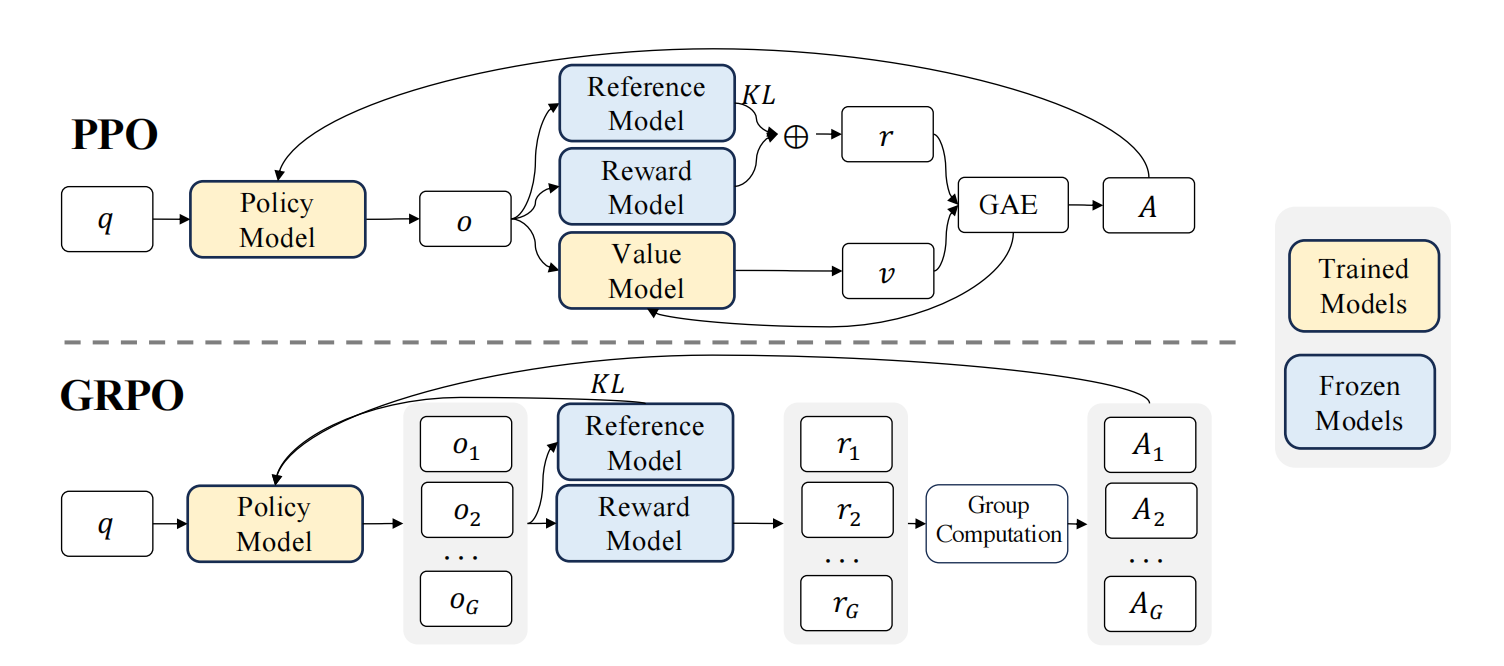
GRPO (Group Relative Policy Optimization) 参考文献 Papers DeepSeekMath_ Pushing the Limits of Mathematical Reasoning in Open Language Models Understanding R1-Zero-Like Training_ A Critical Perspective DeepSeek-R1_ Incentivizing Reasoning Capability in LLMs via Reinforcement Learning 从PPO到GRPO 其中和分别是当前和旧的策略模型,和是从问题数据集和旧策略采样的问题和输出,通过公式来计算,其中有公式,我们需要额外训练一个Critic模型来对进行拟合 PPO的问题有: PPO 中使用的值函数通常是与策略模型大小相当的另一个模型,这带来了显著的内存和计算负担 此外,在 RL 训练期间,值函数被用作方差缩减的baseline,而在 LLM 的上下文中,奖励模型通常只为最后一个 token 分配奖励分数,这...

Reinforcement Learning2-DPO
DPO (Direct Preference Optimization) 参考文献 Papers Direct Preference Optimization__Your Language Model is Secretly a Reward Model 从PPO到DPO PPO的问题是训练流程复杂,训练模型过多,这个是我们推导DPO的初衷 对于PPO整体而言,有如下奖励公式: 我们尝试推导该公式的闭式解,将KL散度进行展开: 我们希望重新配凑出一个KL散度形式的式子: 但是此时不满足一个概率的形式,所以引入配分函数: 上式变为: 又因为不依赖于,所以最小化上式,等同于最小化KL散度,那么理想中的闭式最优解则变为: 根据此对应关系,我们可以重参数化: 由PPO中关于奖励偏好的公式可以得出: 于是由最大似然,我们就得到了DPO的损失函数: 将PPO中的 Bradley-Terry 模型推广到 Plackett-Luce 模型,即从描述两者的序关系模型推广到描述多者的序关系模型: 给定提示词 和一组回答 ,用户会给出一个排列 ,这个排名出现的概率为: 可以理...
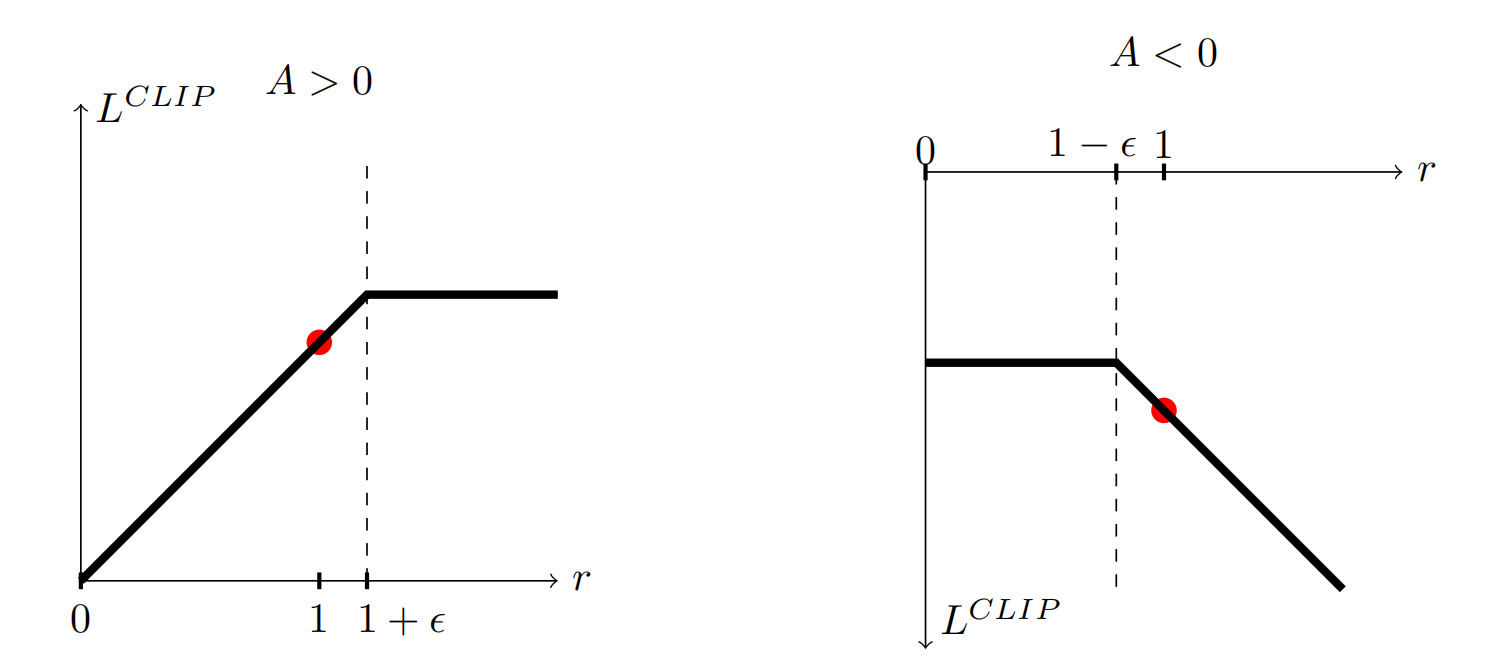
Reinforcement Learning1-RLHF
RLHF 参考文献 Papers Trust Region Policy Optimization Proximal Policy Optimization Algorithms 从传统的策略方法开始 基于策略的强化学习用参数化概率分布 代替了基于值函数的强化学习中的确定性策略 ,在返回的动作概率列表中对不同的动作进行抽样选择 目标函数——最大化reward: 其中 是 agent 与环境交互产生的状态-动作轨迹 ,该策略涵盖所有可能情况 其中,特定的轨迹 在策略 下发生的概率定义为: 策略 :在状态 下,agent有多大概率选择行为 状态转移概率 :在状态下,进行行为后,环境有多大的概率转移到状态 进行求导: 与无关 由蒙特卡洛方法来近似梯度,采样个轨迹样本,其中,那么: 最后,有参数更新公式: 因此,有算法: 一些进一步的设计 回合制奖励 若是可以简化奖励形式为回合制,,则有通用简化形式: 未来总奖励 定义为未来总奖励,即从第 个步骤开始,直到回合结束能获得的所有奖励之和 如果我们考虑因果关系,那么第 时刻做的动作 只能影响未来的奖励,不...
Diffusion9-流视角
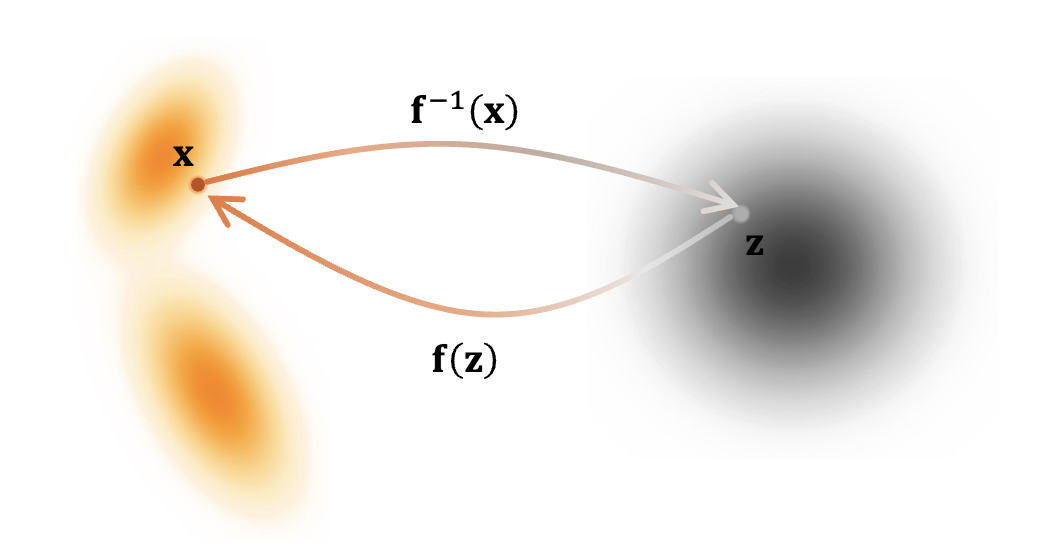
流视角 参考文献 Papers Score-Based Generative Modeling Through Stochastic Differential Equations The Principles of Diffusion Models Residual Flows for Invertible Generative Modeling Variational Inference with Normalizing Flows Invertible Residual Networks A stochastic estimator of the trace of the influence matrix for Laplacian smoothing splines Flow Matching for Generative Modeling Flow Straight and Fast- Learning to Generate and Transfer Data with Rectified Flow Blogs Generative Modeling by Est...
Diffusion8-SDE框架
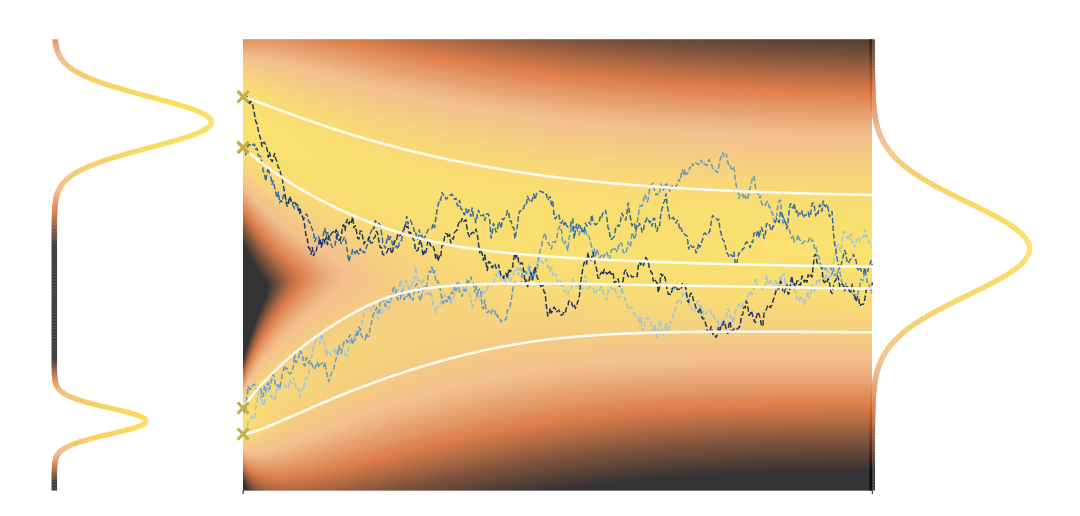
SDE框架 参考文献 Papers Score-Based Generative Modeling Through Stochastic Differential Equations The Principles of Diffusion Models Blogs Generative Modeling by Estimating Gradients of the Data Distribution 正向 SDE NCSN 的前向过程 NCSN 使用一系列递增的噪声水平 。 扰动过程为: 由于 和 都是由同一个干净样本 加上高斯噪声得到的,可以将 表示为 加上一个额外的噪声项 其中,,且 和 是独立的,我们希望求解这个系数 根据定义: 现在,我们通过 来构造 : 由于 是固定样本, 和 是独立的,因此,在给定 的条件下,它们的方差应该满足: 所以: 那么将 定义为: 其中, 那么有: 当 时,我们使用微分近似 : DDPM 的前向过程 DDPM 通过一个方差调度 逐步注入噪声: 对于从 到 的连续化近似,利用近似 ...
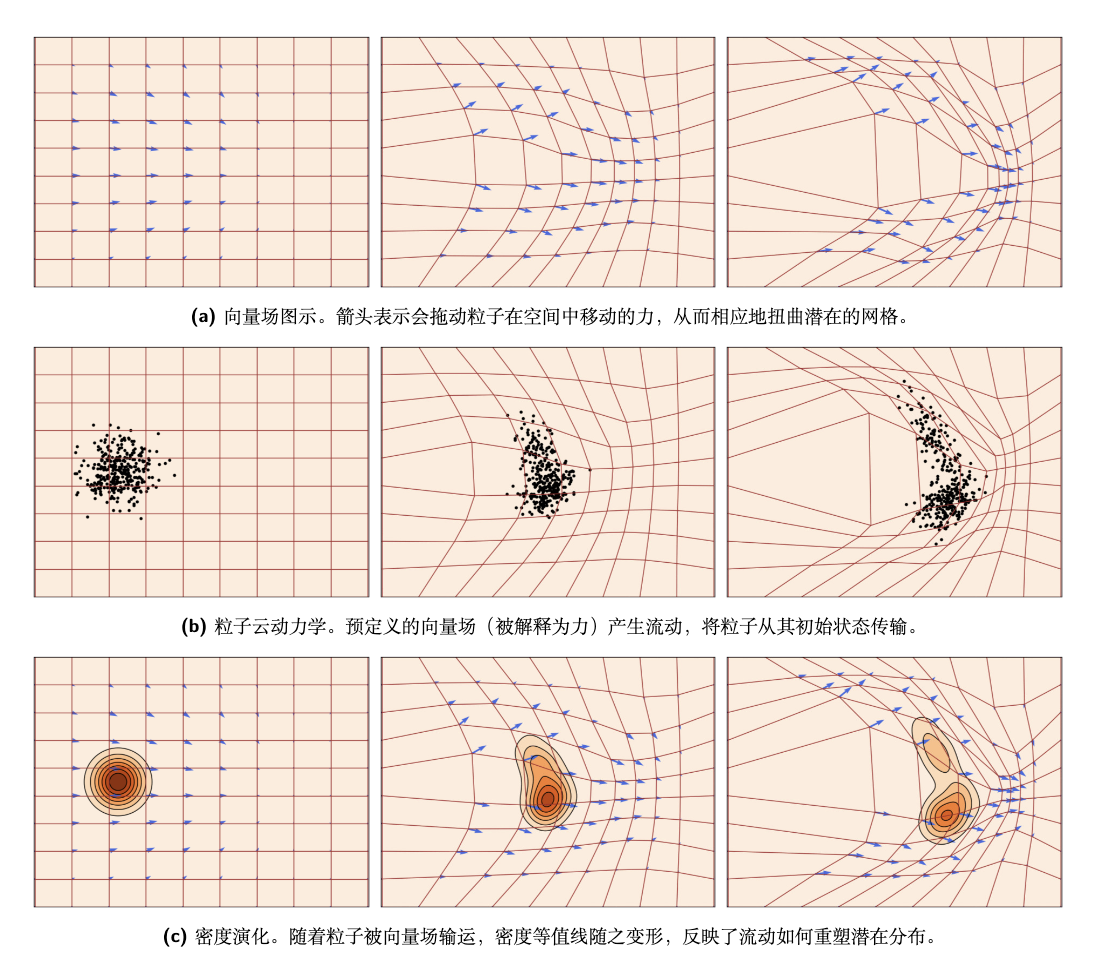
Diffusion7-从密度变换到福克-普朗克方程
概率密度在变换下的演化过程 参考文献 Papers The Principles of Diffusion Models 确定性单步变换 考虑一个作用于 维状态 的确定性、光滑向量场 : 这表示从初始状态 经过一个单位时间步演化到状态 设初始状态 ,则 ,由于概率质量守恒,应用 后的密度可以通过变量变换公式从得到 等价形式(在 坐标下): 线性情形 如果 是线性的,由可逆矩阵 定义(即 ),则: 微积分角度证明 该密度公式直接来源于多元微积分中的变量替换法则 单变量 对于积分 ,变量替换 导致: 多变量 对于 且 ,无穷小体积的变换为: 所以有: 密度公式的推导 概率密度 的一个基本属性是,它可以被视为 Delta 函数在 上的期望值: 其中 ,由于 : 令 ,那么: 代入: 利用 Delta 函数的筛选性质: 在本例中,函数 为: 将 中的 替换为 : 确定性离散多步变换 考虑一个状态序列 ,其中每一步的状态 通过一个光滑双射 演化到 : 初始状态 由于每一步 都是一个光滑双射,根据概率质量守恒,密度的演...
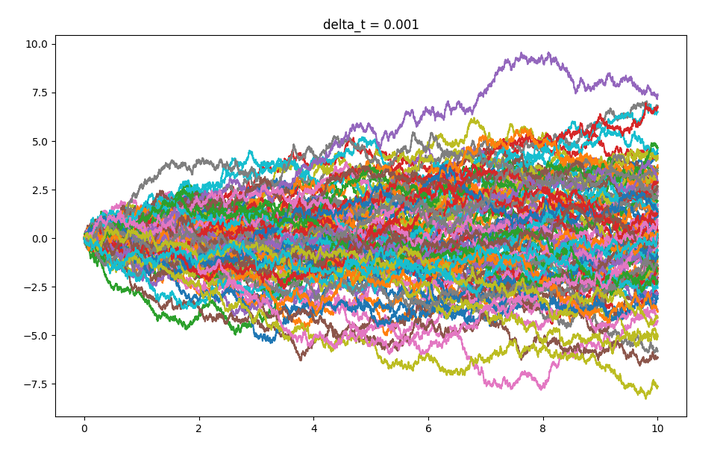
Diffusion6-SDE与伊藤积分
SDE与伊藤积分 参考文献 Papers The Principles of Diffusion Models 从ODE到SDE 从一个描述状态变量 的确定性演化的常微分方程开始: 在小时间步 下对 ODE 进行欧拉离散化: 当 时,这个近似在适当的正则性条件下收敛到 ODE 的精确解 引入随机性 在欧拉离散化中加入一个随机项来引入这种不确定性,从而得到 SDE 的离散形式: :漂移项 :扩散系数 (Diffusion Coefficient),控制了随机项的强度,此处假设其仅依赖于时间 :时间缩放因子,随机游走中的方差与时间步成正比,因此标准差(偏差)与时间步的平方根成正比 :标准高斯噪声 令 ,上式 对应于著名的 伊藤 (Itô) 积分形式的 SDE: 其中 是维纳过程(或布朗运动)的微分形式,其增量 满足 布朗路径几乎处处不可微,但是具有性质,也就是说,在无穷小时间间隔内,布朗路径的增量是一个零均值且协方差为的高斯随机变量 SDE的一般形式 经典黎曼勒贝格积分伊藤积分 由于维纳过程(布朗运动)的轨迹是连续但几乎处处不可微的,经典微积分...
Diffusion5-ODE的基本性质与解法
ODE的基本性质与解法 参考文献 Papers The Principles of Diffusion Models Books 喻文健,《数值分析与算法(第3版)》,清华大学出版社,2020. 常微分方程定义与基本性质 常微分方程描述了一个确定性的演化过程。系统随时间 的状态变化率由以下方程给出: :表示系统在时间 的状态(位置) :是一个向量场(时变速度场),它定义了空间中每一点在每一时刻的“指令”——即变化的方向和大小 可以将求解 ODE 想象为粒子在流体中的运动: 向量场视角: 是一个静态或动态的“箭头景观”,规定了每一点的局部流向 轨迹视角:解 是一条曲线。粒子从起点 出发,其每一步的运动方向(切线方向)都严格遵循向量场 的指引 直觉:一旦初始状态 确定,在满足一定条件下,粒子随时间演化的整个轨迹 就被唯一确定了 解的存在性与唯一性 存在性:是否一定有一条路径能满足方程? 唯一性:从同一点出发,是否只会产生一条路径? 局部存在性与唯一性定理 设 是空间与时间的开区域,设向量场 是定义在该区域上的函数 若函数 满足以下两个条件: 连...
Diffusion4-DDPM与分数视角的形式化统一
形式化统一:SMLD与DDPM 参考文献 Papers Score-Based Generative Modeling Through Stochastic Differential Equations Blogs Generative Modeling by Estimating Gradients of the Data Distribution 回顾: SMLD与DDPM SMLD (Denoising Score Matching with Langevin Dynamics) 训练过程 噪声序列: Noise-Perturbed Distribution: 对于每个噪声 ,原始数据分布 被扰动,得到噪声扰动分布 NCSN: 训练一个噪声条件评分模型 (Noise Conditional Score Network, NCSN) 来估计每个噪声扰动分布的评分函数 ,使其近似满足: 其中,一般来说: 训练目标 推理过程 给定充足的数据和模型容量,最优的基于得分的模型 几乎在 的所有情况下都匹配 接下来,顺序地为每个 运行 步的朗之万 M...

Diffusion3-分数视角
分数视角 参考文献 Papers Score-Based Generative Modeling Through Stochastic Differential Equations Generative Modeling by Estimating Gradients of the Data Distribution Sliced Score Matching: A Scalable Approach to Density and Score Estimation A Connection Between Score Matching and Denoising Autoencoders Estimation of Non-Normalized Statistical Models by Score Matching Blogs Generative Modeling by Estimating Gradients of the Data Distribution Sliced Score Matching: A Scalable Approach to Density a...
