Reinforcement Learning2-DPO
DPO (Direct Preference Optimization)
参考文献
Papers
从PPO到DPO
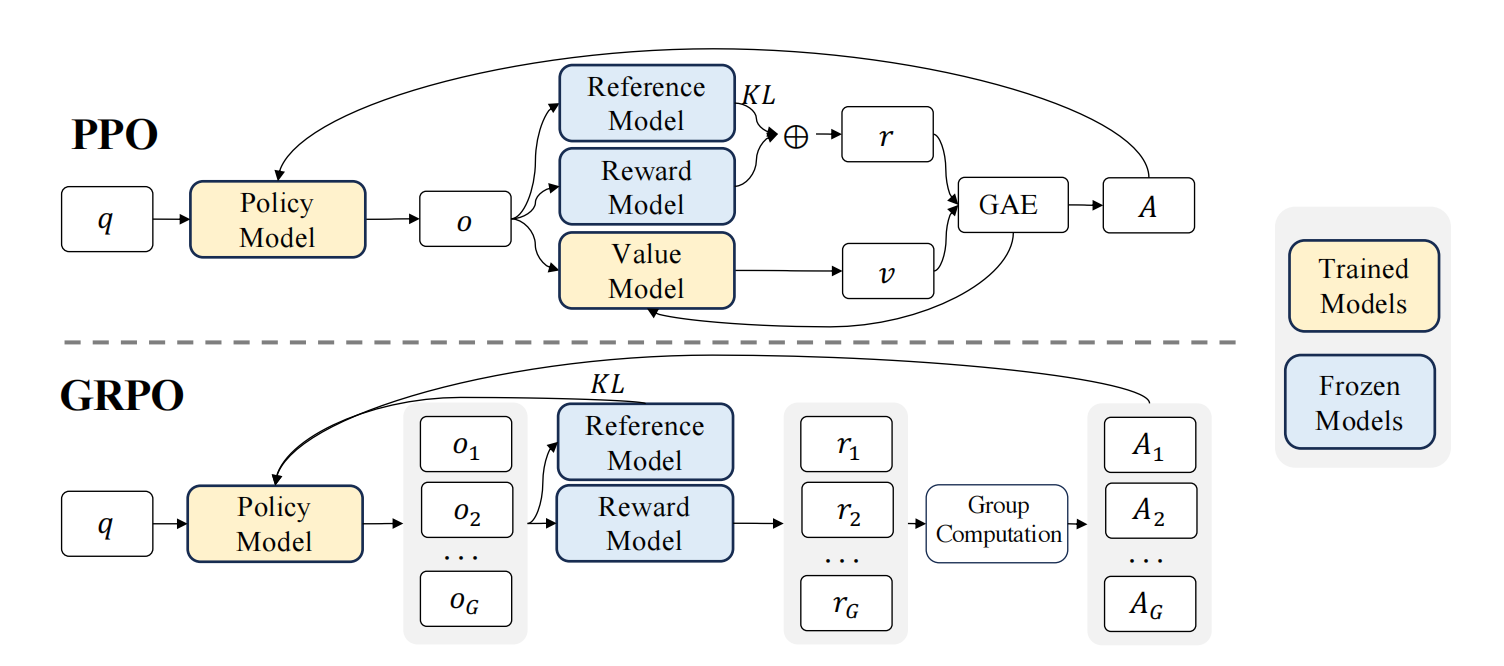
PPO的问题是训练流程复杂,训练模型过多,这个是我们推导DPO的初衷
对于PPO整体而言,有如下奖励公式:
我们尝试推导该公式的闭式解,将KL散度进行展开:
我们希望重新配凑出一个KL散度形式的式子:
但是此时
上式变为:
又因为
根据此对应关系,我们可以重参数化:
由PPO中关于奖励偏好的公式
于是由最大似然,我们就得到了DPO的损失函数:
将PPO中的 Bradley-Terry 模型推广到 Plackett-Luce 模型,即从描述两者的序关系模型推广到描述多者的序关系模型:
给定提示词
可以理解为一个“多次抽奖”模型,第一名是从所有
将重参数化后的奖励代入:
可由此构建损失函数:
训练过程
我们回到二分类的形式,对于DPO的损失函数采取梯度下降:
根据求导法则可以重写为:
其中
由Sigmod函数特性,
代入隐式奖励的定义
- 直观动作:增大模型生成好回答
的概率,减小生成坏回答 的概率 - 动态权重:
项起到了调节作用,如果模型已经能很好地分辨好坏,梯度就会变小;如果模型分不清,梯度就会变大,迫使模型大力学习
应用 Pipeline
有 SFT 时
- 令
- 用
生成数据并让人类标注,形成数据集 - 初始化
,然后直接最小化
无 SFT 时
- 在偏好数据集的“胜出回答”上做一次SFT
- 用
生成数据并让人类标注,形成数据集 - 初始化
,然后直接最小化
进一步理论分析
Your Language Model Is Secretly a Reward Model
由重参数化中的定义:
DPO的整个的优化过程等价于优化一个具有如下奖励参数化形式的 Bradley-Terry 模型:
我们需要回答的一个核心问题就是:将奖励函数强行写成这种对数比率的形式,会不会限制了模型的表达能力?
定义:奖励函数的等价关系
我们称两个奖励函数
其中
引理1: 在 Plackett-Luce(特别是 Bradley-Terry)偏好框架下,属于同一等价类的两个奖励函数会导出完全相同的偏好分布
我们要证明由
由等价公式替换:
引理2: 在带约束的 RL 问题下,属于同一等价类的两个奖励函数会导出完全相同的最优策略
最优策略有如下表达式:
将
定理:在温和的假设下,所有与 Plackett-Luce(特别是 Bradley-Terry)模型一致的奖励函数等价类,都可以通过如下重参数化形式(对数比率)来表示
其中
考虑任意奖励函数
对两边取对数线性化后,我们得到:
其中
利用算子
下面进行唯一性证明,即,在每一个奖励函数的等价类中有且仅有一个奖励函数可以被写成
DPO 这种
假设在同一个等价类里,有两个不同的奖励函数
既然
代入重参数化公式:
合并对数项得:
由对数函数的单调性:
利用概率分布的归一化性质:
因为
由此得出
所以,在每一个奖励函数的等价类中有且仅有一个奖励函数可以被写成 DPO
这种
如果一个等价类里有多个
回顾:PPO不稳定的原因
在强化学习中,我们的终极目标是让参数化模型
等价于最大化其负值:
代入最优策略
其中配分函数
将
展开对数项:
带回后重新组合得到:
等价于:
最后整理得:
被称为 “DPO 等价奖励”,在 PPO 中,我们通常只给模型提供 ,但公式推导告诉我们,完美的奖励信号应该减去那个 是在当前提示词 下所有可能回答的“平均奖励指数”,减去它相当于把奖励去中心化了 - 在 PPO 中,由于
无法直接计算,模型必须通过一个 Critic 网络来猜这个值,如果猜高了,模型会觉得即便很好的回答也是“负反馈”;如果猜低了,模型会觉得垃圾回答也是“正反馈”,这种“猜”的过程引入了巨大的方差 - DPO 在实际计算 Loss
时,是用好答案的公式减去坏答案的公式,在这个减法中,
项被直接抵消掉了,DPO 巧妙地避开了这个“最难猜”的项,从而实现了不需要 Critic 网络也能稳定训练的目标