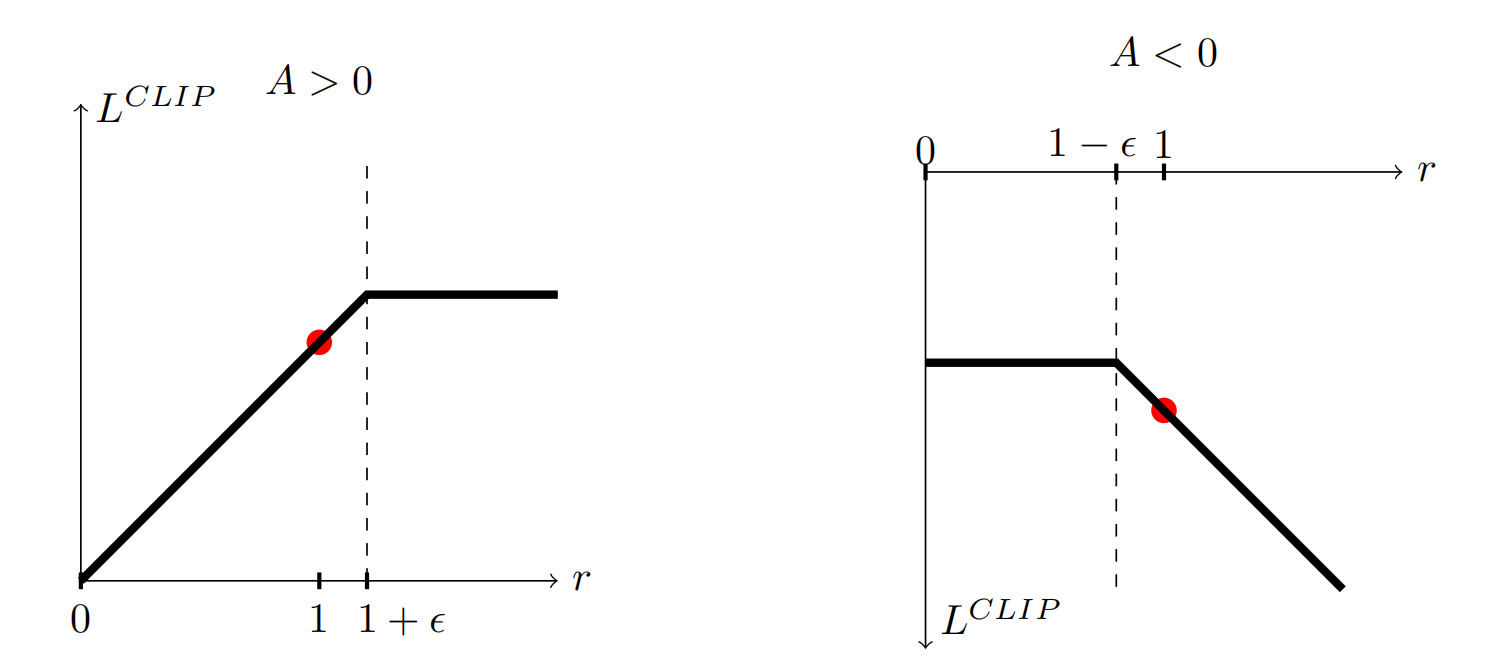Reinforcement Learning3-GRPO
GRPO (Group Relative Policy Optimization)
参考文献
Papers
DeepSeekMath_ Pushing the Limits of Mathematical Reasoning in Open Language Models
DeepSeek-R1_ Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
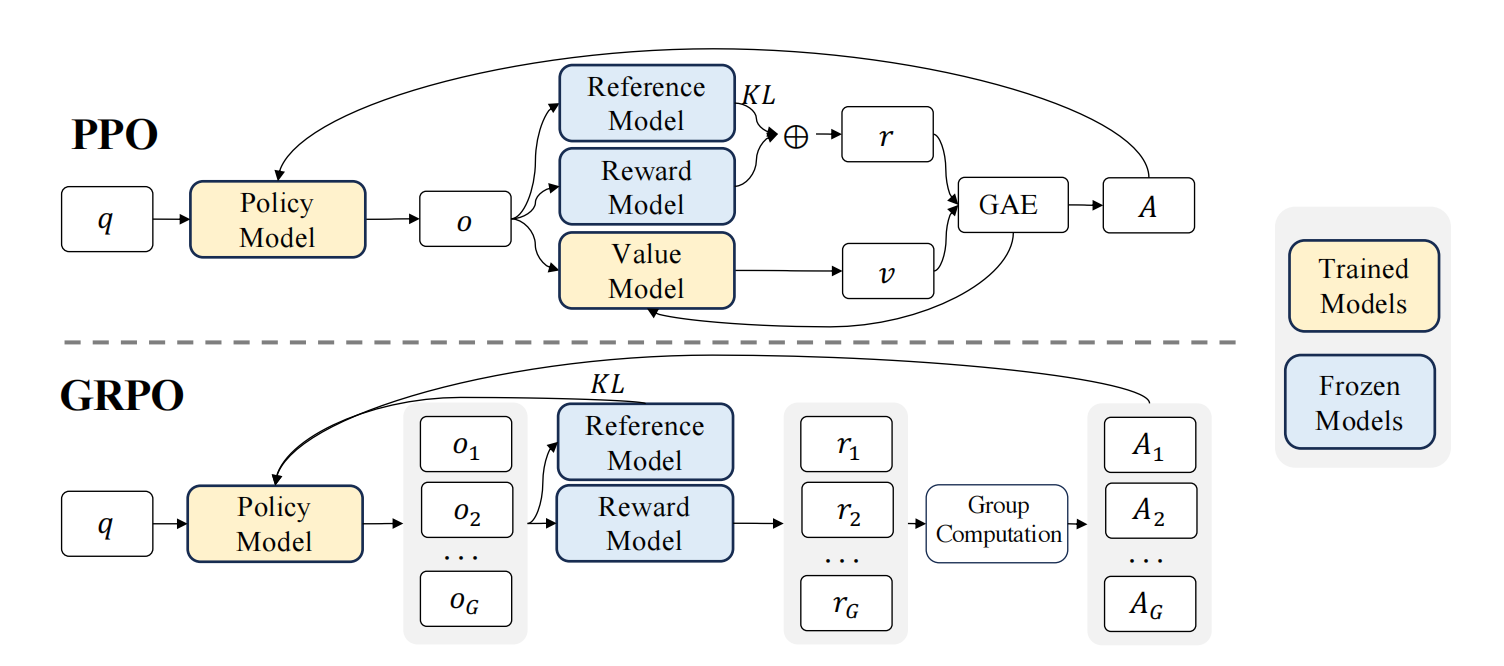
从PPO到GRPO
其中
PPO的问题有:
- PPO 中使用的值函数通常是与策略模型大小相当的另一个模型,这带来了显著的内存和计算负担
- 此外,在 RL 训练期间,值函数被用作方差缩减的baseline,而在 LLM 的上下文中,奖励模型通常只为最后一个 token 分配奖励分数,这可能会使为每个 token 精确训练值函数变得复杂
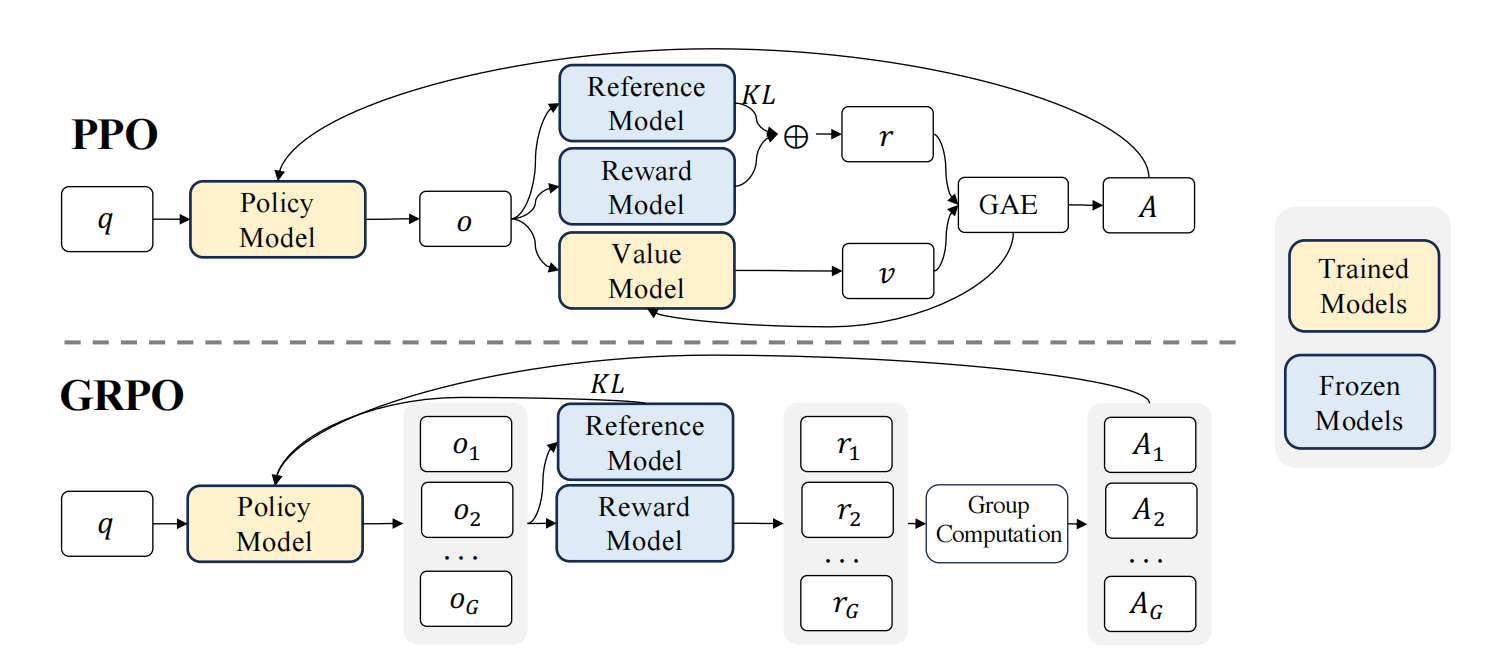
所以提出GRPO!
针对每一个问题,生成多个回答,而对于每一个时刻的基准值而言,不再采用Critic模型去预测,而是由这一组中平均水平来充当
其中的KL散度通过一种特定的无偏估计器去计算:
结果监督
对于每个问题
结果监督在每个输出
过程监督
结果监督仅在每个输出的末尾提供奖励,这在处理复杂的数学任务时,对于监督策略可能是不充分且低效的
过程监督,它在每个推理步骤的末尾提供奖励
给定问题
其中
随后,过程监督将每个 token 的优势函数计算为后续所有步骤归一化奖励之和,即:
在实际的大模型对齐的流程中,往往两种策略进行混合使用,即保证大模型能够在大方向上建立起奖励感,又能够在中间逻辑上进行正确的推理
整体的算法如下图所示:

Dr. GRPO
此处我们采用使用了结果监督的GRPO,我们认为此时的GRPO中存在着两个偏置:

回答级长度偏差:这源于公式中除以了
(回答长度), - 对于正优势(回答正确):长度越短,分母
越小,梯度更新幅度越大,这会导致模型在正确答案中偏好短回答 - 对于负优势(回答错误):长度越长,分母
越大,惩罚力度反而被稀释了,这会导致模型在错误答案中偏好长回答
- 对于正优势(回答正确):长度越短,分母
问题级难度偏差:这源于除以了标准差
,在组内得分标准差很小的情况下(例如题目太简单或太难,大家得分都是 1 或 0),该项会极大增加更新权重,这导致不同难度的题目在优化过程中权重不均
所以,提出Dr. GRPO:
在GRPO的语境下,我们通常最大化如下目标函数的值:
其中
对其求梯度得:
下面对于
通常,我们将基准值设置为未来累积奖励的期望(即状态价值函数),并令
在结果奖励的情况下,未来的累积奖励直接简化为总回报
在GRPO语境下,应该设置
根据上述式子,将其放置于PPO的语境下,同样有:
上面计算的