Paper2poster 论文解读
Paper2Poster: Towards Multimodal Poster Automation from Scientific Papers
Overview

两个贡献:
(1)提出基准测试和度量标准: 这是首个针对海报生成的基准测试,它通过以下四个方面来评估生成的海报:
视觉质量: 生成海报的语义与人类设计的海报的契合度
文本连贯性: 海报中语言的流畅性
整体评估: 通过“视觉语言模型(VLM)作为评判者”来评分的六项细致的美学和信息标准
PaperQuiz: 衡量海报传达论文核心内容的能力,方法是让 VLM 回答根据海报生成的问题
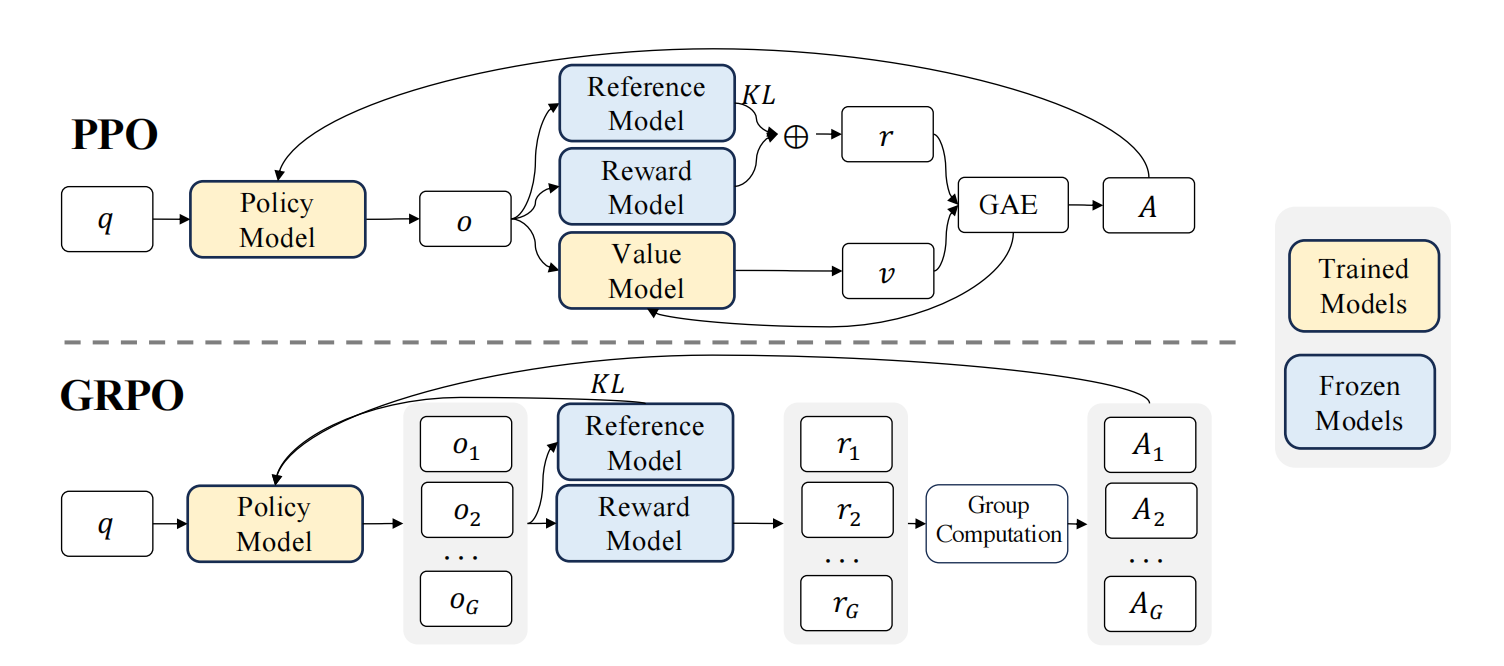
(2)PosterAgent: 一个新颖的、自上而下、融入视觉反馈的多智能体管道,专门用于海报生成。它包含三个主要组成部分:
解析器(Parser): 将论文内容提炼成结构化的“资产库”。
规划器(Planner): 将文本和视觉元素对齐到二叉树布局中,以保持阅读顺序和空间平衡。
绘图器-评论器循环(Painter–Commenter Loop): 通过执行渲染代码并利用 VLM 的反馈来优化每个面板,以消除溢出并确保对齐
Paper2Poster Benchmark
Data curation
data source (POSTERSUM dataset) -> data sampling (length control + latest version)-> final dataset
Evaluation Metrics
视觉质量指标 (Visual Quality Metrics)
视觉相似度 (Visual Similarity)
衡量生成的宣传海报 (
首先,使用 CLIP 图像编码器 (
然后,计算这两个图像嵌入之间的余弦相似度:
与传统的基于分布的度量(例如 FID)相比,这种方法在实例层面操作,能够直接衡量单个海报图像之间的语义一致性和整体内容相似性。
图表相关性 (Figure Relevance)
此指标评估生成海报中的每个图表是否在上下文上是恰当的,检查图表与其在原始论文中对应的文本内容之间的语义关联度。
对于从生成海报
然后计算每个图表图像嵌入与其对应文本嵌入之间的余弦相似度
如果海报中包含图表 (
如果海报中没有包含任何图表 (
Textual Coherence (文本连贯性)
这个指标关注的是海报中所有文本(包括标题、正文、图表描述等)的质量。它旨在确保海报上的文字清晰、流畅、自然,符合语法和语义规则,从而提高读者的可读性和理解力
计算方法:
使用标准化的“Perplexity (PPL)”(困惑度)来量化文本连贯性
将整个海报的文本输入到预训练的语言模型Llama-2-7b-hf中,语言模型会为每个词元
困惑度定义为:
VLM进行整体评估
输出分数: 对于每一张海报图像,VLM 会在 6 个具体的评估标准上打分,分值范围是 1 到 5 分
两大类:
审美分数 (Aesthetic Score):
- 元素质量 (Element Quality)
- 布局平衡 (Layout Balance)
- 吸引力 (Engagement)
信息分数 (Information Score):
- 清晰度 (Clarity)
- 内容完整性 (Content Completeness)
- 逻辑流程 (Logical Flow)
重点的prompt可以参照Paper2Poster/utils/prompt_templates下:
aesthetic_element_judge.yaml、aesthetic_engagement_judge.yaml、
aesthetic_layout_judge.yaml、
imformation_content_judge.yaml、
imformation_logic_judge.yaml、
aesthetic_low_level_judge.yaml
Paper Quiz
1. Quiz问题的生成
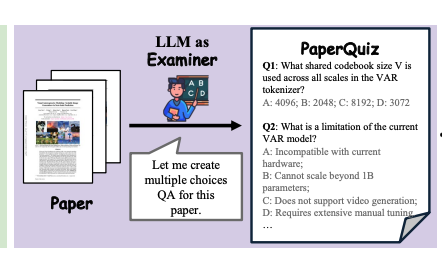
输入每一篇论文的 PDF 文件,gpt-o3为每篇论文生成100道多项选择题:
50 道逐字问题 (Verbatim Questions): 这些问题可以直接从论文文本中找到答案
50 道解释性问题 (Interpretive Questions):这些问题需要更高层次的理解能力才能回答
2. Quiz问题的回答

将海报图像展示给六个VLM,模拟了从“休闲读者”到“专家读者”的不同理解水平,这些 VLM 只能基于海报来回答 quiz 问题
3. 评估海报效果
通过比较不同海报版本在这些 quiz 上的得分,可以确定哪张海报最能有效地传达原始论文的内容。
4. 计算公式
海报作为一种视觉媒介,其文本长度通常远少于论文。如果一个模型只是简单地将大量论文文本复制到海报上,它可能会在 quiz 上获得高分,但这并不符合海报简洁明了的特点。
论文引入了一个基于长度的惩罚机制,对原始 Quiz 分数
其中:
PaperAgent
1. Parser:对于Poster进行粗粒度压缩
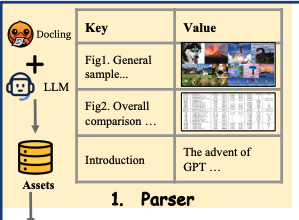
先利用工具将pdf文件转换为markdown,再利用LLM生成类似于JSON文件的大纲
Text assets
对于文本,按照段落进行分割,每个键是一个章节标题,每个值是对应段落的摘要
Visual assets
对于视觉内容,每一个键是图表标题或表格标题,每一个值是提取的图像文件
2. Planner:构建海报
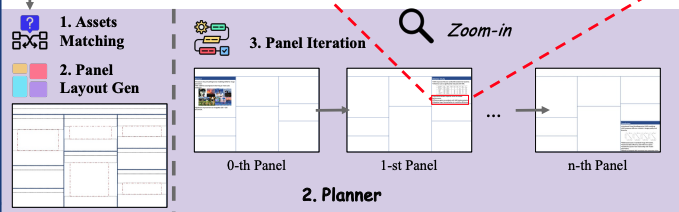
Asset matching
将上文提到的Text assets与Visual assets进行一个匹配,使用LLM对这里面相关的内容进行语义对齐,生成一组(章节,图片)对
Layout generation
在一个给定的白板上确定布局,需要考虑内容长度,保留阅读顺序和内容宽高比,使用一种二叉树布局策略,将这种约束为每一个章节确定一个明确的面板
Panel iteration
使用下面的Painter–Commenter循环,一次次迭代绘制面板
3. Painter–Commenter

绘图器(Painter)
使用LLM接受章节摘要并生成要点,即海报上呈现出来的主要文本内容
利用python-pptx库生成代码并渲染成图像
评论器(Commenter)
绘图器渲染出面板图像之后,使用一个VLM作为评论器评估质量,提出有针对性的视觉反馈,进行一个迭代,直到评论器发出成功信号或者到达最大迭代次数时才停止
为防止VLM的幻觉问题,
- 使用了
zoom-in策略,使评论器重点关注面板的特定区域,而不是进行整体评估,从而提高判断的准确性 - 使用上下文参考提示,提供给评论器两个示例,一个展示了严重文本溢出,另一个展示了理想布局,帮助评论器更准确识别