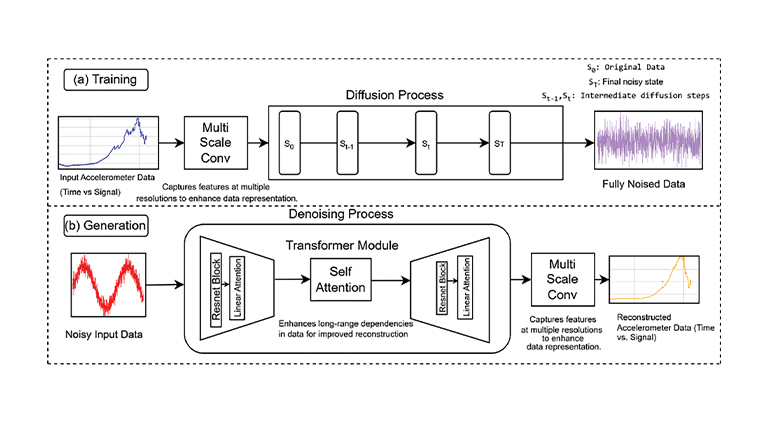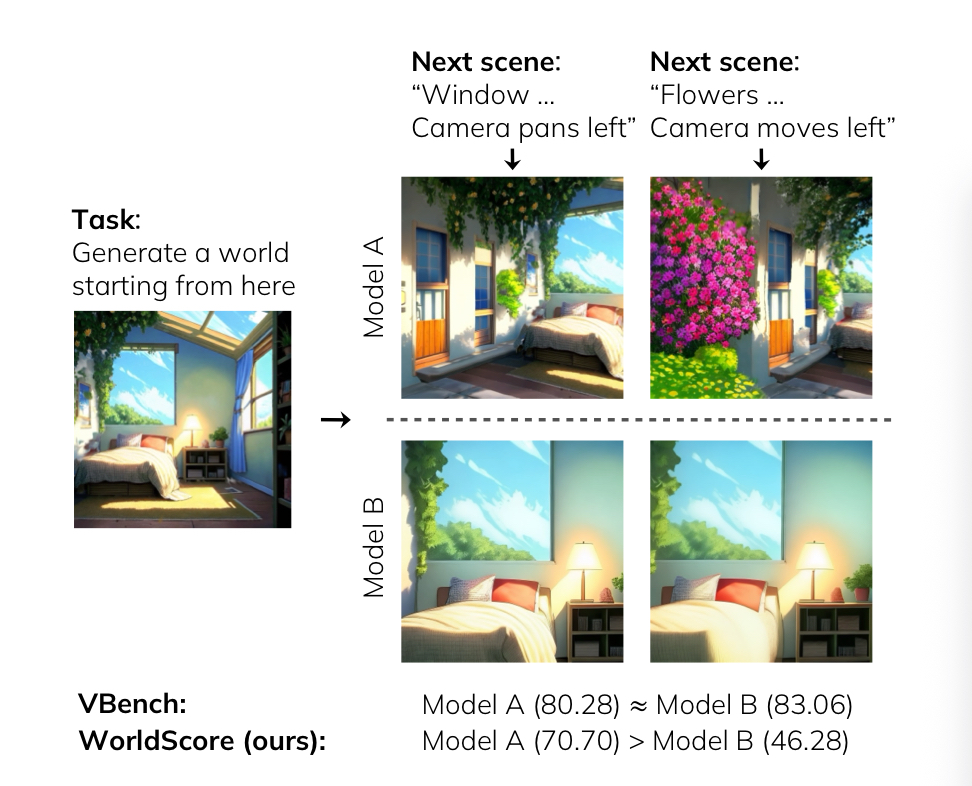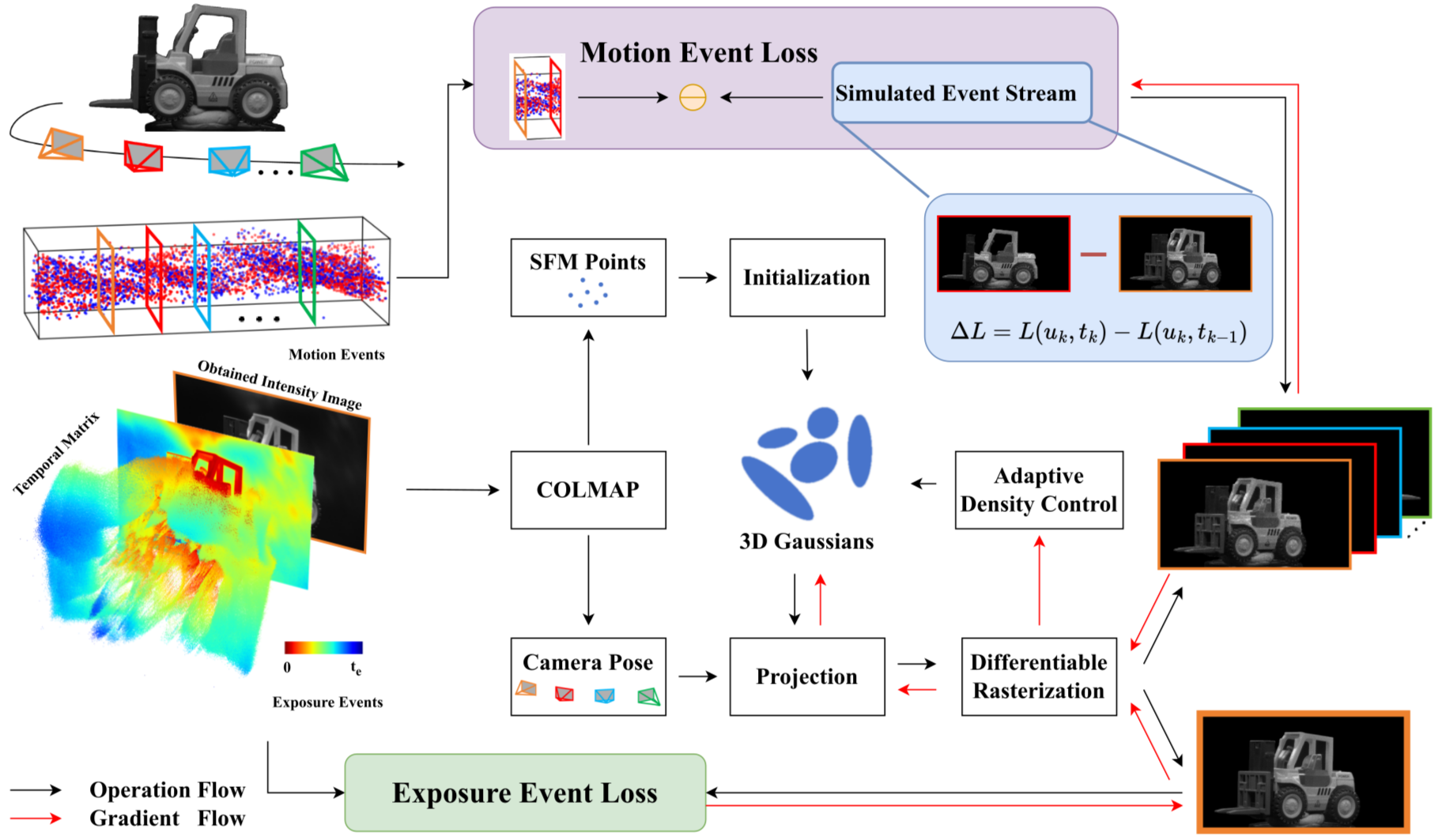
3dgs 知识解析
3DGS(3D gaussian splatting) 一言以蔽之:3DGS是将三维空间用3D高斯椭球建模,并且通过splatting的方式映射到一个二维平面上。 一 sfm初始化稀疏点云 SfM初始化稀疏点云是重建三维场景的第一步,其目的是从一组无序的二维图像中,恢复相机的姿态以及场景中稀疏的三维点集(云) 1. 特征点检测与描述 在每张输入图像中检测具有代表性和可重复性的2D特征点(用SIFT和SURF) 为每个检测到的特征点生成一个描述符,这是一个紧凑的数值向量,用于唯一标识该特征点 2. 特征点匹配 对于每一对图像,通过比较它们各自的特征点描述符来找出匹配点对,即在两张图像中对应于场景中同一物理点的2D特征点 最近邻匹配:找到描述符距离最近的匹配点 比率测试:如果最近邻与次近邻之间的距离比率低于某个阈值,则认为该匹配有效,以消除歧义 RANSAC:使用RANSAC算法来剔除错误的匹配点,并估计图像间的几何关系 3. 两视图几何 在至少两张图像之间建立几何关系 计算本质矩阵或基础矩阵: 对于一对匹配的图像,通过这些匹配点可以计算出本质矩阵(如果已知相机内参)或基础矩阵...

On-the-Fly Method 论文解读
On-the-fly Reconstruction for Large-Scale Novel View Synthesis from Unposed Images Overview 3D 高斯散点(3DGS)这样的辐射场方法,可以从照片中方便地重建场景,并实现free-viewpoint navigation。 但是,存在着两个问题: 时间开销很大:1)使用Structure from Motion方法进行相机姿态估计和2)3DGS优化在相机拍摄完成后都需要几分钟或者几小时不等的时间 SLAM 方法与 3DGS 结合可以加快处理速度,但在相机视角跨度较大(wide baseline)或场景规模较大时表现不佳。 本文章方法优点: 提出了一种在线处理方法,可以在拍摄完成后立即获得相机姿态和训练好的 3DGS 表示。(边拍边建模) 可以同时处理密集拍摄(如视频)和宽基线拍摄(如每几步拍一张)的有序图像序列,并能适用于大规模场景。 提出的方法: (1)快速的初始姿态估计方法,结合了learned features与mini bundle adjustment 利用深度学习模型...
Paper2poster 论文解读
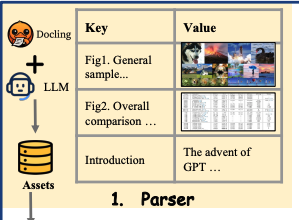
Paper2Poster: Towards Multimodal Poster Automation from Scientific Papers Overview 两个贡献: (1)提出基准测试和度量标准: 这是首个针对海报生成的基准测试,它通过以下四个方面来评估生成的海报: 视觉质量: 生成海报的语义与人类设计的海报的契合度 文本连贯性: 海报中语言的流畅性 整体评估: 通过“视觉语言模型(VLM)作为评判者”来评分的六项细致的美学和信息标准 PaperQuiz: 衡量海报传达论文核心内容的能力,方法是让 VLM 回答根据海报生成的问题 (2)PosterAgent: 一个新颖的、自上而下、融入视觉反馈的多智能体管道,专门用于海报生成。它包含三个主要组成部分: 解析器(Parser): 将论文内容提炼成结构化的“资产库”。 规划器(Planner): 将文本和视觉元素对齐到二叉树布局中,以保持阅读顺序和空间平衡。 绘图器-评论器循环(Painter–Commenter Loop): 通过执行渲染代码并利用 VLM 的反馈来优化每个面板,以消除溢出并确保对齐 Pape...

VGGT 论文解读
VGGT Overview 前馈神经网络: 从一张或多张图片中预测3d场景的关键属性: 相机参数 深度图 点云 3d轨迹 优点: 不依赖传统优化,快,好,不需要先验,从图像序列中一次性输出3d场景信息。 Method Basic Definition VGGT的输入是张同一场景不同角度的RGB图片序列, VGGT transformer是一个映射 ,将这个图片序列映射到了场景3d属性序列中: 对于某一张(一帧)图片而言: 相机参数(内参 + 外参): :相机旋转角 :平移向量 :视场角 FOV (),假设中心在图像几何中心(内参) 深度图: 设第 张图像为 ,其像素网格定义为: 每个像素的位置用二维坐标 表示。 模型为每张输入图像 预测一个对应的深度图 。其中,每个像素位置 的预测深度值记作 ,满足: 表示:第 张图像中,像素点 所“看到”的真实世界中的三维点距离相机的深度; 3d 点云图: 一张图上面 个点 每一个点对应一个三维坐标 沿用上面说的深度图的定义:,对应一个三维点。 3d点轨迹。 给定一张图像中的某个像素,找到...