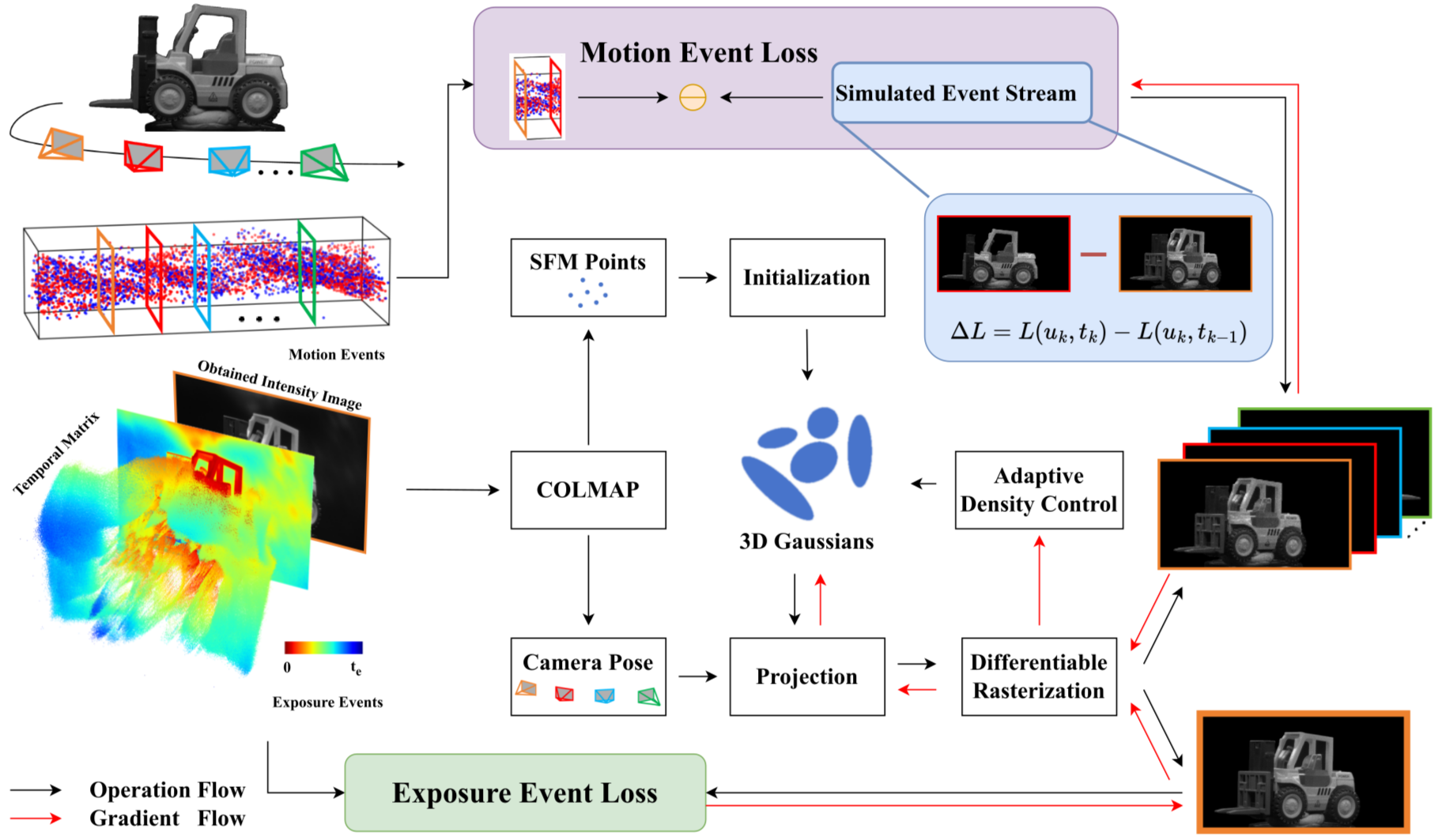
On-the-Fly Method 论文解读
On-the-fly Reconstruction for Large-Scale Novel View Synthesis from Unposed Images
Overview
3D 高斯散点(3DGS)这样的辐射场方法,可以从照片中方便地重建场景,并实现free-viewpoint navigation。
但是,存在着两个问题:
时间开销很大:1)使用Structure from Motion方法进行相机姿态估计和2)3DGS优化在相机拍摄完成后都需要几分钟或者几小时不等的时间
SLAM 方法与 3DGS 结合可以加快处理速度,但在相机视角跨度较大(wide baseline)或场景规模较大时表现不佳。
本文章方法优点:
提出了一种在线处理方法,可以在拍摄完成后立即获得相机姿态和训练好的 3DGS 表示。(边拍边建模)
可以同时处理密集拍摄(如视频)和宽基线拍摄(如每几步拍一张)的有序图像序列,并能适用于大规模场景。
提出的方法:
(1)快速的初始姿态估计方法,结合了learned features与mini bundle adjustment
利用深度学习模型从图像中提取出鲁棒且独特的特征
在更小的数据子集(更少的图像/点)上执行 BA,或者使用一种更简化、计算量更小的 BA 版本
(2)提出了高斯原语位置与形状的直接采样方法,在需要的地方逐步生成高斯点,从而大幅加速训练过程
传统 3DGS 通常依赖于一种叫densification的过程,即根据渲染误差较大的区域由梯度驱动来添加新的高斯
提出的是一种更智能的、基于概率的方法来直接采样高斯基元的位置和形状减少了对大量“gradient-driven densification”的需求
系统可以随着新数据的不断输入,持续地细化相机的位姿和三维场景表示
(3)采用增量式方法来处理大规模场景:通过可扩展的辐射场构建机制,逐步对高斯原语进行聚类,并将其存储为锚点,从而从 GPU 中卸载不再活跃的数据聚类后的高斯原语还会被逐步合并,以保持在每个视角下 3DGS 的必要规模,不造成资源浪费。
当新数据进入窗口,旧数据离开窗口时,窗口内的三维场景点或高斯基元可能会被聚类(分组)和合并(简化或组合),以保持效率并减少冗余
“锚点”指的是地图中策略性选择的、高度可靠的点或区域,这些点在优化过程中保持固定或被赋予更高的权重
锚点提供了一个稳定的参考框架,可以防止误差累积和漂移,即使滑动窗口移动,也能确保在大范围内的地图一致性
方法组件

一种快速但近似的初始姿态估计方法,采用精心设计以实现GPU-friendly的mini BA
一种直接采样方法,通过估计每个像素生成高斯的概率来确定高斯基元的位置和形状,这显著减少了对稠密化的需求
一种非常高效的姿态和3DGS联合优化方法,得益于前两个步骤,改善了姿态和辐射场的初始版本
一种在线可扩展的优化方法,使用一组滑动锚点,逐步在空间中聚类3DGS基元,从而能够处理大规模场景
组件1:轻量化的位姿估计
Feature extraction
每一张输入的图像,系统会应用一个快速的关键点检测器和描述符 ,每帧生成6144个关键点
采用了XFeat结构来完成这个过程
Bootstrapping
(1)等待初始帧:
系统首先会等待直到接收到一定数量的初始帧,这在实验中被设定为
(2)穷举匹配: 一旦收集到足够的初始帧,系统会在这些帧的每对图像之间执行穷举匹配。这意味着对这N_init帧中的所有可能对进行特征匹配
(3)优化相机参数和点云位置: 基于这些匹配,系统通过最小化重投影误差来优化以下参数
- 焦距
- 相机姿态
- 3d点位置
高效策略
固定每个3D点被观测的图像数量
常规做法:在传统的三维重建方法中,一个三维点可能在任意数量的图像中被观测到。这导致在优化时,每个三维点对应的方程数量是不固定的,使得问题结构非常复杂。
论文策略:为了简化问题,强制设定每个三维点只能被固定数量的图像观测到。这意味着无论场景或数据如何,每个三维点在所有参与优化的图像中,只会被一个预设的、固定数量的子集看到。
固定大小的稀疏雅可比矩阵:
在优化算法中,我们需要计算重投影误差关于待优化参数的雅可比矩阵
由于每个3D点被固定数量的图像观测,这意味着雅可比矩阵中的非零块的布局和大小是固定不变的。这个矩阵是稀疏的,因为它的大部分元素都是零。
如何高效
- 易于构建:由于结构固定,构建雅可比矩阵
变得非常简单和直接,不需要复杂的动态内存管理或结构推断 - 高效求解方法:
和 这两个子矩阵本身也是稀疏的,因为他们固定了非零块的大小,这使得内存可以被预先分配。这意味着在程序运行前,系统就知道需要多少内存,并一次性分配好,避免了运行时的内存碎片和频繁的内存分配/释放操作 - 由于每个块都是固定大小且可以独立计算,这使得算法能够充分利用GPU的批处理能力。(GPU特别擅长执行大量相同类型的小型、独立计算任务,通过将这些固定大小的计算任务打包成批次并同时在GPU上执行,可以实现极大的并行加速)
- 避免使用Ceres这样的通用优化库,虽然非常灵活和强大,但是耗时
Pose Estimation for Subsequent Frames
对于每一帧新接收到的图像,系统会执行以下步骤来估计其相机姿态并更新场景:
步骤1:关键点匹配与3D-2D对应关系建立
新帧的关键点会与最近的
为了建立3D-2D对应关系(即新帧中的2D关键点对应于场景中的哪个3D点),系统会尝试估计这些新的关键点在三维空间中的位置。这主要通过两种方式实现:
- 三角测量(triangulation):如果一个关键点在新帧和至少两个已注册的旧帧中都被观测到,并且这些旧帧的相机姿态已知,那么可以通过三角测量来计算该关键点的三维坐标
- 渲染深度(rendered depth):如果三角测量失败(如,关键点只在新帧和一帧旧帧中可见,或基线不足),系统会使用已有的场景表示(例如,3D高斯场)渲染出的深度信息来估计关键点的三维位置(从已知的就帧的相机处给这个3d高斯场渲染一个深度图,并根据这个深度图获取点坐标)
步骤2:相机姿态估计与内点筛选
利用建立的3D-2D对应关系,系统使用一个GPU并行的RANSAC(Random Sample Consensus)算法来估计新帧的相机姿态并筛选出inliers,即符合当前模型的大多数匹配点),同时有效处理掉outliers的数据。
在RANSAC内部,使用了自定义的
mini bundle adjustment方法作为每次迭代的姿态估计器。这意味着RANSAC在选择一组最小样本点后,会使用这个轻量级的BA来更精确地计算姿态,并评估模型的质量。
步骤3:姿态精炼
在通过RANSAC获得初始姿态和内点集合后,系统会运行20次迭代的mini bundle adjustment。这次BA会使用所有被RANSAC识别出的内点,以进一步精炼新帧的相机姿态,使其更加准确。
步骤4:3D高斯基元创建
对于每个成功通过三角测量获得三维位置的关键点,系统都会为其创建一个3D高斯基元
声明:
尽管一个关键点由于传递性匹配可能在许多图像中被看到,但为了维护一个gpu-friendly的固定大小的问题,监督被限制在最近的
恢复机制:bootstrapping的重新运行条件
为了确保方法在某些挑战性场景下(如相机几乎不移动的纯旋转场景,或因累积误差导致的尺度漂移)能够恢复,系统设计了重新运行bootstrapping过程的条件:
平均相机距离过近:如果最近的二十个相机姿态之间的平均距离低于
,系统会重新启动引导过程。这通常发生在相机几乎没有移动(例如,纯旋转或非常缓慢的平移),导致三角测量基线不足,难以准确估计3D点深度和相机姿态时 投影误差过低时的姿态更新:如果当前的优化后重投影误差低于1像素,这表明姿态估计已经非常准确。在这种情况下,系统会通过将最近的
帧(在 bootstrapping过程中初始化的帧数)的姿态与“先前估计的姿态”进行对齐来更新它们。这可以帮助纠正任何小的漂移,并确保姿态的一致性
组件2:通过估计每个像素生成高斯的概率来确定高斯基元的位置和形状的一种采样方法
对于高斯基元的要求
传统的3DGS方法在场景重建过程中,会频繁进行“密集化”操作,这个过程既有可能引入额外的计算负担,也可能存在不足之处,如可能产生过多冗余的基元。
论文方法是希望直接从每一帧中采样一组3D高斯基元,在处理每一帧时,系统会有策略地决定在哪里放置新的高斯基元,而不是依赖于后处理的密集化步骤。这个方法需要新增加的高斯基元满足两个要求:
覆盖未见区域或增加细节:新的高斯基元应该被放置在相机之前没有捕捉到的区域,以扩展场景的范围;或者在那些虽然已经被初步重建但细节不足、比较粗糙的区域,增加更多的细节表示
避免冗余:采样过程必须是智能的,不能在某个区域放置超过实际需要的高斯基元
对于在图像上2d点选取的要求
传统的3dgs SLAM方法在初始化3D高斯基元时对新加入的帧有常见的两种采样策略以及不足:
- 均匀分布:一些方法选择在图像中均匀地分布高斯基元。这种方法无法根据输入图像的具体特征和细节进行自适应调整
- 基于关键点放置:另一些方法则选择将高斯基元放置在图像的关键点位置。但是仅基于关键点放置的高斯基元往往过于稀疏,通常需要进行额外的**密集化(densification)**步骤,使得时间和存储负担加重
新方法对于在图片上采样遵循两个核心准则:
集中于高频细节和不连续区域:3D高斯基元应该被密集地放置在图像中具有高频细节的区域(对应着场景中的不连续性),例如物体的边缘、纹理变化剧烈的地方,这些地方包含了场景中最重要的结构信息,非常重要
位于不连续性两侧:高斯基元不仅要集中在不连续性处,更要精细地位于每个不连续性(即边缘)的两侧。这样是为了能够准确地表示边缘,可以更好地捕捉边缘的形状、锐利度和深度信息,从而实现更真实的场景重建
如下图所示:

具体采样过程
为了满足上述的对于高斯基元的要求和对于图像上2d点选取的要求,该方法引入了一种基于概率的采样机制。即对于新帧中的每一个像素,系统会计算一个概率值,这个概率值决定了该像素是否应该生成一个新的高斯基元。概率越高,生成基元的可能性越大
以下是整个采样流程的示意图:

步骤1: 初始化概率
基于局部空间梯度计算像素生成高斯基元的初始概率
基于
即该区域越包含重要的图像特征(如边缘或细节),越有可能生成高斯基元
步骤2: 添加惩罚项
该步骤是为了满足要求:在已有足够基元表示边缘的区域,避免放置过多的高斯基元
引入了惩罚项
这个公式的计算方式步骤1的公式几乎相同,但关键的区别在于其输入图像
确保了模型不会在同一个地方重复添加高斯基元,从而实现更高效和精简的场景表示
步骤3:得到最终概率表示
最终的高斯添加概率
是一个精妙的平衡机制,在图像中需要更多细节的区域(由
步骤4:深度估计策略
4.1 初步单目深度估计
使用了模型Depth-Anything-2来估算这些选定像素的单目深度。单目深度估计是仅凭一张
2D 图像来预测每个像素到相机的距离
4.2 深度与三角化匹配对齐
由于单目深度估计可能存在显著误差,因此需要进行校正。论文将单目深度与三角化匹配(通常通过多视图几何方法从不同图像中的对应点计算得出 3D 位置)进行对齐。
4.3 基于Correlation Volume的深度精化
这个相关性体的计算是围绕着之前估算出的单目深度值进行的。这意味着单目深度提供了一个“粗略”的深度范围,然后相关性体方法在这个范围内进行更精细的匹配和深度确定
先采用了一个密集特征提取器,并将其应用于每一帧图像。为每帧图像生成了一个逐像素的特征图
。 接着,对于当前帧的每个像素位置,系统会根据一个自适应匹配方法,选择一个最合适的邻近帧。确保了每个像素只使用一个邻近帧进行匹配,旨在最大化深度消歧
通过在逆深度范围
内进行均匀采样,构建候选深度向量 对于每个候选深度
,当前帧 的像素会被重投影到选定的邻近帧 。重投影会根据相机参数和候选深度计算出像素在邻近帧中的新坐标 针对每个候选深度
,通过计算当前像素 在当前帧 的特征向量 与重投影点 在邻近帧 的特征向量 之间的内积来构建相关性向量 : 最终会得到一个包含
个值的相关性向量 ,每个值对应一个候选深度 的相似度 在
上,通过二次拟合,找到二次曲线峰值对应的深度,该深度即被认为是最佳深度
步骤5:高斯椭球尺寸参数初始化
在标准的 3DGS 中,高斯基元的尺度是根据其近似的 3D 3-最近邻点之间的平均距离来初始化的。
但在图像的不连续区域(如锐利边缘),它倾向于生成过大的高斯基元且对异常值敏感
使用最近邻搜索耗费时间
改进的尺度初始化方法
利用
假设像素
3d空间的s为
相机焦距
像素对应的估计深度
转换后得到的
组件3: 一种非常高效的姿态和3DGS联合优化方法
初始状态:对于每一张新图像,系统会从相机姿态以及高斯基元的直接采样位置和大小的初始估计开始(上述两个方法)
并非所有新图像都会被注册为关键帧,只有当关键点的中位数位移超过屏幕宽度的3%时,该帧才会被注册为关键帧,关键帧执行30次3dgs迭代优化
学习率是为每个高斯基元单独分配的。学习率会根据每个高斯最初引入场景的时间进行动态调整
相机通过6D法表示旋转,接收梯度更新。这些更新来源于高斯基元的位置和旋转优化。但不会从球谐函数传播
为了首先捕捉场景的低频细节、加速优化并避免陷入局部最优,采用了
coarse-to-fine的策略。即每当添加一张新图像时,都会以的下采样率进行训练.然后,每进行五次迭代,我们就会递减 l 的值,直到图像达到完整尺寸。 初始姿态估计方法在联合优化相机姿态和高斯基元时能够有效防止局部最优 ,能够处理比SLAM更宽基线的图像数据。此外,方法的增量特性非常适合处理大型环境.
组件4:一种在线可扩展的优化方法
为了实现处理大规模环境,我们采取了特定的策略
以往处理大规模环境的解决方案会引入巨大的开销,这些开销主要体现在创建、优化和维护分层数据结构上
该方法在图像处理过程中维护一个Active Gaussian集合。这个集合包含当前正在GPU上进行优化和渲染的高斯基元
随着时间的推移,一些较早放置的高斯基元从当前相机位置看可能会变得非常小,对渲染图像很小。对于这些基元,我们会将其从GPU内存转移到CPU内存中,并存储在一个anchor处。这使得场景表示成为一组可以根据需要重新加载到GPU的簇
步骤1:检测何时创建锚点
基元大小定义:
对于相机
触发锚点创建的条件:
当系统处理到序列中的当前相机
若有超过40%的活跃高斯基元的大小
触发后:
创建一个新的锚点,并将这些变得非常小的高斯基元合并起来,从GPU卸载到CPU内存中
步骤2:聚类与合并
一个锚点存储以下信息:
- 锚点在三维空间中的坐标。
- 高斯基元集合:包含被复制到此锚点中的所有高斯基元
- 优化状态:这些基元在被复制时的优化参数和状态
- 关键帧:用于优化这些高斯基元的历史关键帧信息
进一步合并
- 选择需要合并的基元:系统会随机选择被认为太精细基元中的
部分 - 对于每一个被选中的基元,找到它的
个最近邻。 - 找到最近邻后,这些被选中的基元及其
个最近邻进行递归合并 - 所有未被选中进行合并的基元则保持不变
步骤3:滑动窗口式的锚点创建
随着基元合并,新的Active Gaussian集合诞生
在下一轮迭代是这个集合会被优化,产生新的锚点
capture流程结束后,最后的Active Gaussian集合被存放在最后的锚点中
新视角创建
当需要渲染一个新视角时,系统会首先确定相机当前位置距离哪个锚点最近。然后,它会主要渲染该最近锚点所包含的Gaussians
但当两个锚点与相机的距离非常接近时,系统会进行高斯融合
融合权重的计算
假设相机距离两个最近的锚点分别为
系统会计算一个距离比率
- 如果
,这意味着最近的锚点 比第二个锚点 近很多,在这种情况下,最近锚点的融合权重为 ,而另一个锚点的权重为 - 若
,最近锚点的融合权重 :