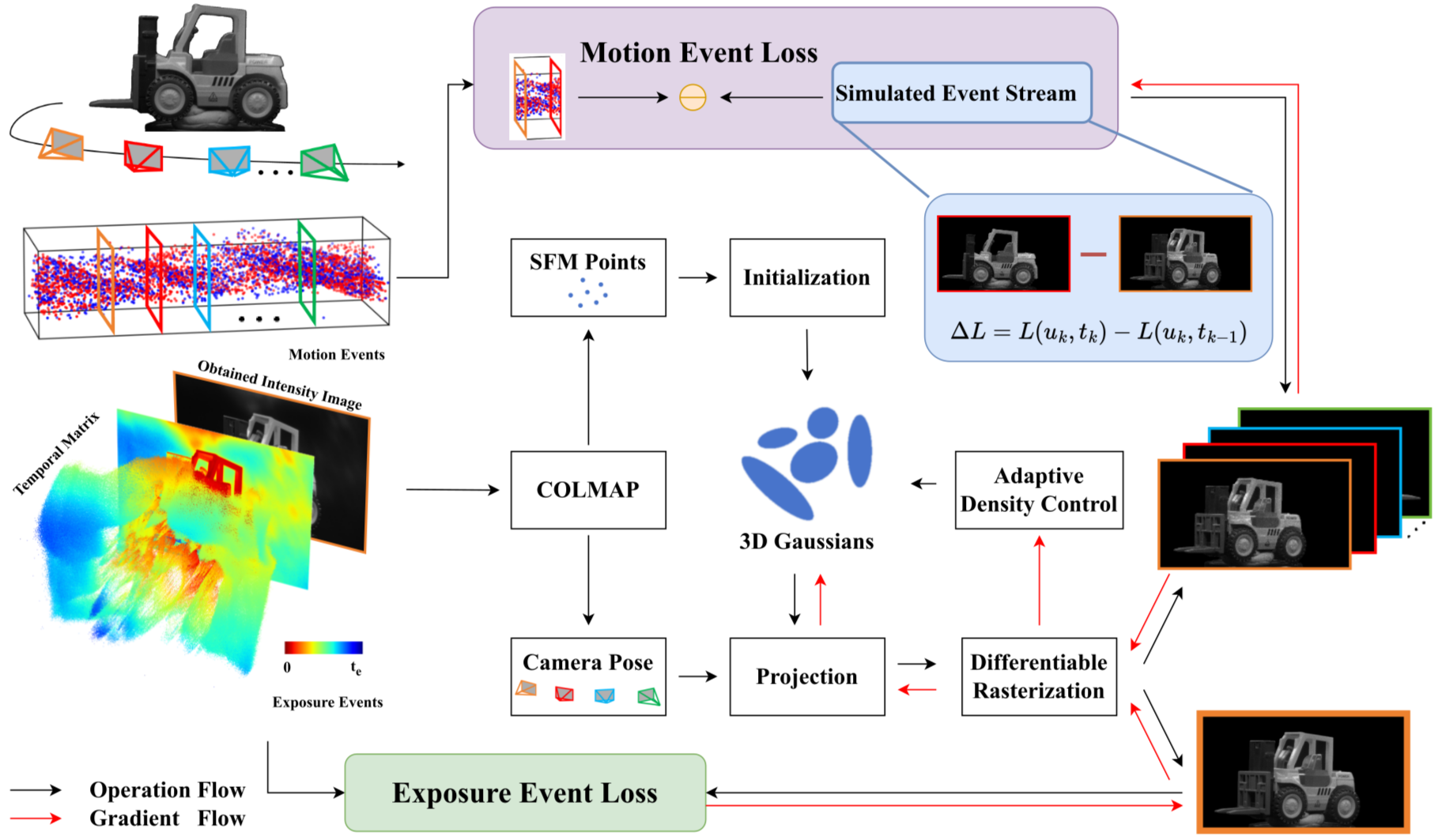
defslice_expand_and_flatten(token_tensor, B, S): """ Processes specialized tokens with shape (1, 2, X, C) for multi-frame processing: 1) Uses the first position (index=0) for the first frame only 2) Uses the second position (index=1) for all remaining frames (S-1 frames) 3) Expands both to match batch size B 4) Concatenates to form (B, S, X, C) where each sequence has 1 first-position token followed by (S-1) second-position tokens 5) Flattens to (B*S, X, C) for processing Returns: torch.Tensor: Processed tokens with shape (B*S, X, C) """ # token_tensor : (1, 2, X, C) # 提取第一帧“query token”,复制 B 次 # (1, 1, X, C) => (B, 1, X, C) query = token_tensor[:, 0:1, ...].expand(B, 1, *token_tensor.shape[2:]) # 提取第二帧“other token”,复制B * (S - 1)次 # (1, 1, X, C) => (B, S-1, X, C) """ 注意这里没有 .clone() 或 .repeat(),意味着 在计算图上,所有 batch 实际上都共享同一个token 参数的 memory 引用,只是逻辑上“看起来”每个batch 有独立的token。 """ others = token_tensor[:, 1:, ...].expand(B, S - 1, *token_tensor.shape[2:]) # Concatenate # (B, 1, X, C) + (B, S-1, X, C) => (B, S, X, C) combined = torch.cat([query, others], dim=1) # Flatten, 与 patch token 对齐 # (B, S, X, C) => shape (B*S, X, C) combined = combined.view(B * S, *combined.shape[2:]) return combined
# Note: We have two camera tokens, one for the first frame and one for the rest # The same applies for register tokens self.camera_token = nn.Parameter(torch.randn(1, 2, 1, embed_dim)) self.register_token = nn.Parameter(torch.randn(1, 2, num_register_tokens, embed_dim))
# Initialize parameters with small values nn.init.normal_(self.camera_token, std=1e-6) nn.init.normal_(self.register_token, std=1e-6)
# Expand camera and register tokens to match batch size and sequence length camera_token = slice_expand_and_flatten(self.camera_token, B, S) register_token = slice_expand_and_flatten(self.register_token, B, S)
# Concatenate special tokens with patch tokens tokens = torch.cat([camera_token, register_token, patch_tokens], dim=1)
# by default, self.aa_block_size=1, which processes one block at a time for _ inrange(self.aa_block_size): ifself.training: tokens = checkpoint(self.frame_blocks[frame_idx], tokens, pos, use_reentrant=self.use_reentrant) else: tokens = self.frame_blocks[frame_idx](tokens, pos=pos) frame_idx += 1 intermediates.append(tokens.view(B, S, P, C))
return tokens, frame_idx, intermediates
def_process_global_attention(self, tokens, B, S, P, C, global_idx, pos=None): """ Process global attention blocks. We keep tokens in shape (B, S*P, C). """ if tokens.shape != (B, S * P, C): tokens = tokens.view(B, S, P, C).view(B, S * P, C)
if pos isnotNoneand pos.shape != (B, S * P, 2): pos = pos.view(B, S, P, 2).view(B, S * P, 2)
intermediates = []
# by default, self.aa_block_size=1, which processes one block at a time for _ inrange(self.aa_block_size): ifself.training: tokens = checkpoint(self.global_blocks[global_idx], tokens, pos, use_reentrant=self.use_reentrant) else: tokens = self.global_blocks[global_idx](tokens, pos=pos) global_idx += 1 intermediates.append(tokens.view(B, S, P, C))
pos = None ifself.rope isnotNone: pos = self.position_getter(B * S, H // self.patch_size, W // self.patch_size, device=images.device) # (self.patch_start_idx = 1 + num_register_tokens) ifself.patch_start_idx > 0: # do not use position embedding for special tokens (camera and register tokens) # so set pos to 0 for the special tokens pos = pos + 1 pos_special = torch.zeros(B * S, self.patch_start_idx, 2).to(images.device).to(pos.dtype) pos = torch.cat([pos_special, pos], dim=1)
for i inrange(len(frame_intermediates)): # concat frame and global intermediates, [B x S x P x 2C] concat_inter = torch.cat([frame_intermediates[i], global_intermediates[i]], dim=-1) output_list.append(concat_inter)
defforward(self, aggregated_tokens_list: list, num_iterations: int = 4) -> list: """ Forward pass to predict camera parameters. Args: aggregated_tokens_list (list): List of token tensors from the network; the last tensor is used for prediction. num_iterations (int, optional): Number of iterative refinement steps. Defaults to 4. Returns: list: A list of predicted camera encodings (post-activation) from each iteration. """ # 取出最后的token (B, S, P, 2*C) tokens = aggregated_tokens_list[-1]
deftrunk_fn(self, pose_tokens: torch.Tensor, num_iterations: int) -> list: """ Iteratively refine camera pose predictions. Args: pose_tokens (torch.Tensor): Normalized camera tokens with shape [B, 1, C]. num_iterations (int): Number of refinement iterations. Returns: list: List of activated camera encodings from each iteration. """ B, S, C = pose_tokens.shape # S is expected to be 1. pred_pose_enc = None pred_pose_enc_list = []