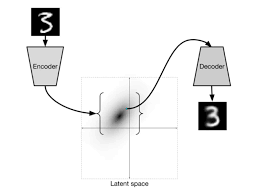
Diffusion3-分数视角
分数视角
参考文献
Papers
Score-Based Generative Modeling Through Stochastic Differential Equations
Generative Modeling by Estimating Gradients of the Data Distribution
Sliced Score Matching: A Scalable Approach to Density and Score Estimation
A Connection Between Score Matching and Denoising Autoencoders
Estimation of Non-Normalized Statistical Models by Score Matching
Blogs
Generative Modeling by Estimating Gradients of the Data Distribution
Sliced Score Matching: A Scalable Approach to Density and Score Estimation
基本设定
分数生成建模,即从一个由独立同分布(i.i.d.)样本
其中:
- 分数(Score): 概率密度
的分数被定义为 ,即对数概率密度的梯度场 - 分数网络(Score Network): 一个由
参数化的神经网络 ,它将被训练来近似 的分数,即 - 生成建模目标: 利用数据集学习一个模型,用以生成来自
的新样本
整体框架而言,分数生成模型旨在通过训练一个分数网络来估计数据分布的梯度(分数),然后利用这些梯度配合朗之万动力学来生成新样本
从EBMs的视角看分数函数的优势
对于EBMs来说,
但是,如果引入分数函数:
Score-based Model 的优化目标
Fisher Divergence
分数匹配的优化目标:最小化模型分数
Score
Matching: 解决
分部积分化简
我们接下来通过分部积分的方式来解决这个问题
一维简化推导
对于一维随机变量,费雪散度可以展开为:
多维分数推广
将分部积分推广到多维数据,即分数匹配目标函数:
其中,
问题
由于涉及到对于矩阵迹的计算,所以在处于高维数据时,会有很高的计算开销
高维问题解决1: Denoising Score Matching
对于
对于
我们对于
将
定义
所以说:
那么高维问题就转化为:
其中:
带入原式:
这样可以优化出来
高维问题解决2: Sliced Score Matching
SSM的核心思想是:与其匹配高维的整个分数向量场
- 原理: 两个向量场
和 只有当它们在所有随机方向 上的投影都相等时,才证明这两个向量场本身是相等的 - 优势: 投影将
维向量场的匹配问题转换成了标量场的匹配问题,从而避开了计算整个 矩阵
所以,我们定义:
这个式子也被称为 Sliced Fisher Divergence
其中,
- 标准高斯分布:
- 球形均匀分布:
即 是一个 维单位球面上均匀采样的方向向量
切片 Fisher 散度
展开
下面展示如何快速的计算
- 第一次梯度操作:计算分数函数
- 第二次梯度操作:计算
,即 ,然后将结果与 做点积
由于
与原始 SM 的对比
假设
朗之万动力学与朗之万采样
我们已经通过上述的score matching方法,成功学习到了分数场,下面需要借助分数场进行生成
朗之万动力学
朗之万动力学是一种MCMC采样算法,可以在不知道完整概率密度函数
- 步长 (
): 控制每一步的移动距离和噪声强度 - 分数项 (
):根据分数函数(梯度),将样本 推向概率更高的区域 - 噪声项 (
): 随机热噪声(布朗运动),确保算法能够探索整个分布空间,避免卡在局部最优解
收敛性
理论上,要求步长
朗之万采样
我们已经训练了一个模型
其中,
通过这个过程,利用训练好的神经网络模型
Naive Score-based Generative Modeling的问题
流形假设
真实世界中的数据(例如,图像、文本、语音等)虽然存在于一个高维空间(ambient space,例如一张
的彩色图片对应 维空间),但它们实际上只集中在这个高维空间中一个或几个低维子空间上,这些子空间被称为低维流形(low-dimensional manifold)
这个假设意味着我们只需要学习和理解数据在这个低维流形上的结构和变化,而不是整个高维环境空间
Score-based Generative Modeling在流形上的两大困难
困难一: Undefined Score Function
如果数据严格限制在一个低维流形
困难二:Inconsistent Score Function
原始的分数匹配理论要求数据分布
在支撑集不覆盖整个空间时,原始的分数匹配目标函数将是不一致的,即使神经网络具有无限容量,并且我们完美地最小化了目标函数,训练出的
表现: Low data density regions (低维流形之外)
Inaccurate Score Estimation with Score Matching

训练出来的分数估计函数在低密度区域(即数据点稀疏的区域)非常不准确,因为低密度区域的真实数据点很少
由费雪散度:
在高密度区域,
因此,训练过程倾向于忽略低密度区域的分数准确性
Slow Mixing of Langevin Dynamics
当数据分布是多峰的(混合高斯分布),且不同“峰”之间被数据稀疏的低密度区域分隔开时,朗之万动力学无法在合理的时间内在这些模式之间高效地跳转,即混合
如果 MCMC 链无法充分混合,就无法正确地遍历整个分布空间,导致最终的样本集不能准确反映各个模式的真实相对权重
数学分析局限性
这种缺陷是分数函数本身的性质导致的
假设目标分布
模式 1 (在
模式 2(在
在两个分离的模式内,分数函数
朗之万动力学仅依赖分数函数进行采样,因此,如果朗之万链随机初始化在一个模式内,它会有效地沿着该模式的梯度移动,但无法感知到该模式应该占据多大的比例
(
理论上,朗之万动力学仍然可以混合,但需要极小的步长和极大的步数才能在低密度“山谷”中成功跳跃

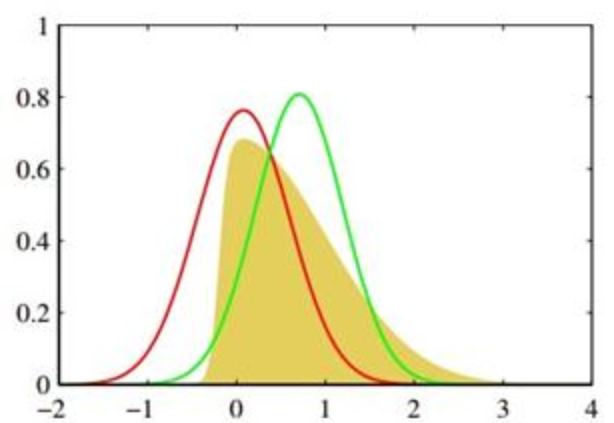
图 3(a) 是精确采样(反映了真实的权重
) 图 3(b) 是朗之万动力学采样,如图所示,朗之万动力学采样的样本在两个模式之间的相对密度是错误的
图 3(c) 展示了使用退火朗之万动力学 采样的结果,能够恢复两个模式之间的相对权重
Noise Conditional Score Networks (NCSN)
模型采用了同时使用多尺度噪声扰动的方法
使用
- Noise-Perturbed Distribution: 对于每个噪声
,原始数据分布 被扰动,得到噪声扰动分布 - NCSN: 训练一个噪声条件评分模型 (Noise Conditional Score Network,
NCSN)
来估计每个噪声扰动分布的评分函数 ,使其近似满足:
训练目标
对于任意给定的噪声而言
且:
那么对于所有的
是一个正权重函数,通常选择为 - 该目标函数
可以通过评分匹配方法进行优化
推理:Annealed Langevin Dynamics
在训练完噪声条件得分模型
几点实用建议:
- 选择
作为一个 项的等比数列,其中 足够小,而 应与 相当 - 使用U-Net skip connections对得分模型
进行参数化 - 在测试时使用得分模型时,对其权重应用指数移动平均