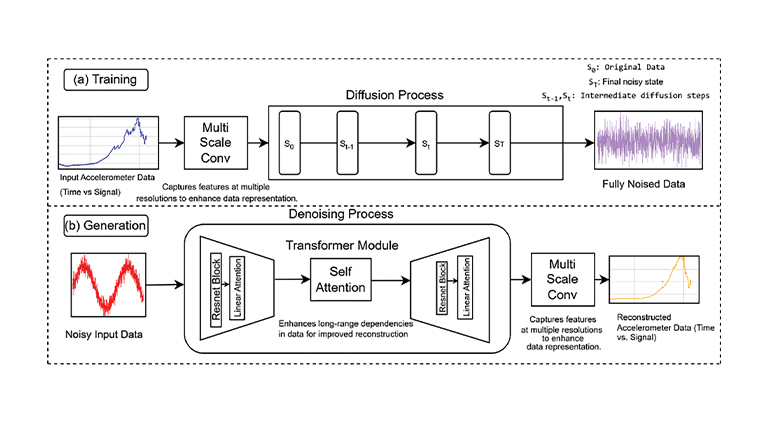
Diffusion1-DPM与DDPM
Diffusion的数学推导与具体实现
参考文献
1.DPM

Diffusion的前向过程(Forward Process)
前向过程是一个固定的马尔可夫链,它逐步向数据中添加高斯噪声,直至数据完全变成纯噪声,即
用数学公式表示如下:
其中,
前向过程的关键特性
通过重参数化,可以在任意时间步
定义
则对上文公式进行重参数化有:
这个公式是训练阶段的核心,它可以直接从原始数据
Diffusion的反向过程(Reverse Process)
反向过程是一个由模型学习的马尔可夫链,从纯噪声
这个过程的每一步都是一个由神经网络参数化的条件高斯分布:
其中,
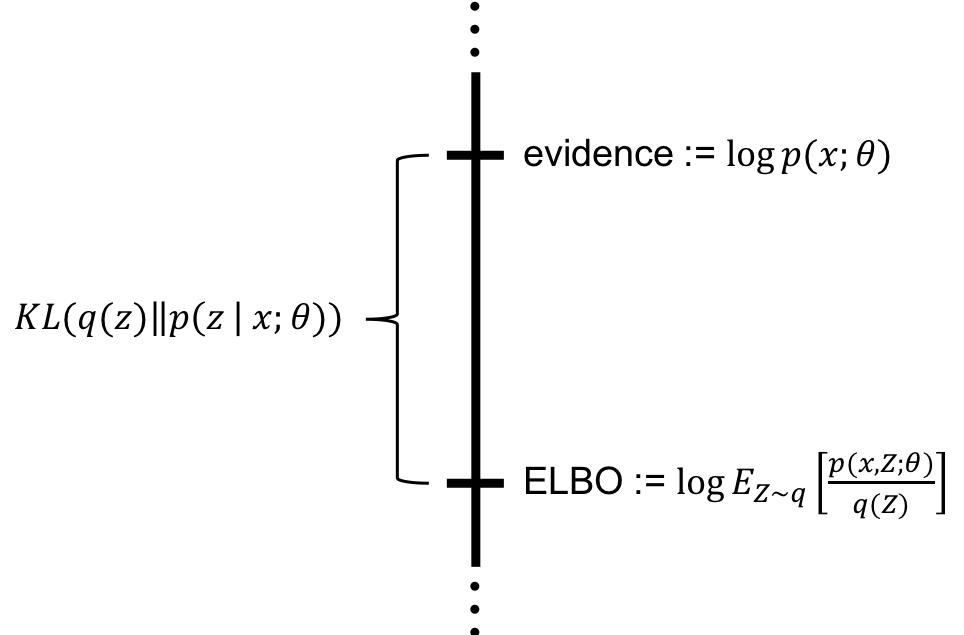
训练目标与ELBO
在潜在变量模型(如变分自编码器VAE和扩散模型)中,我们通常无法直接计算数据
是联合分布,表示模型中的前向和反向过程 是前向过程的联合概率分布
形态1:
:这是由模型的反向过程定义的从 到 的路径上的概率,它代表了模型从噪声生成数据的过程 :这是由DDPM中固定的前向过程定义的从 到 的路径上的概率
形态2:
展开联合分布推导可得:
整个扩散过程(包括前向和反向)是一个马尔可夫链(系统的下一个状态只依赖于当前状态,与过去的历史状态无关)
对联合概率
应用链式法则: 模型假设反向过程是一个马尔可夫链。这意味着,在第
步去噪得到 时,也只依赖于当前状态 ,与更远的未来状态 无关 对于前向过程而言,也是一个马尔可夫过程
将它们代入ELBO的定义,然后使用对数和的性质:
这个式子中的每个项都有其物理意义:
:是一个常数项,因为 是一个标准正态分布,与模型参数无关,实际训练可以忽略这个项
形态3:
由形态2:
形态3.1
引入
形态3.2 直接转换
有关训练
与VAE相同,训练的目标是最大化ELBO
因为
其中,
计算后验
首先通过贝叶斯公式将后验概率转化为先验概率:
此时
其中,
两个高斯分布
使用该公式本身就能够保证归一化问题
之后,我们要对
计算
显然:
对于
我们将其重新整理为关于
忽略所有不含
将上式与标准高斯分布
- 在标准高斯形式中,二次项是
,在我们的表达式中,二次项是 - 在标准高斯形式中,一次项是
,在我们的表达式中,一次项是
因此,
计算后验协方差(
令
利用恒等式
代入:
那么就有:
计算后验均值
带入公式:
那么:
即对于:
对其中的每一个KL散度而言,都可以通过计算Rao-Blackwellized方法求解而不是通过有显著方差的Monte Carlo方法求解
2.DDPM:Diffusion Models and Denoising Autoencoders
新的训练目标与参数设定
前向过程与模型设计
决定前向过程的
- 前向过程
中没有可学习参数 变为常数,可以忽略
反向过程与模型设计
反向过程定义为高斯分布:
协方差
协方差矩阵
两种极端的固定选择
:对应于原始数据 时的最优选择 :对应于 是一个确定点时的最优选择 - 这两种选择分别对应于逆向过程熵的上下界
均值
当逆向过程的协方差固定为
可以将
- 其中
是前向过程的真实后验均值,可以解析 - 所以,优化
最直接的方法是让模型 去预测真实的后验均值
为了简化目标,引入了重参数化技巧:
将此带入真实后验均值
将这个展开式代入
为了最小化损失,
基于上述公式,一种特定的参数化
模型不再直接预测均值
将参数化后的
- 优化复杂的ELBO的
项,等价于优化一个简单的、加权的MSE Loss,该Loss要求模型预测真实噪声
- 这个目标函数形似去噪得分匹配(Denoising Score Matching)
新的
同时也自然提出了训练目标的简单形式:
训练过程

- 从真实数据分布中采样一张原始数据
- 从
均匀地采样一个时间步长 - 从标准正态分布中采样一个纯噪声向量
:执行一次梯度下降,最小化关于 和 预测的 MSE 损失 - 重复直至收敛
采样过程
 训练完成后,通过逆向过程从噪声生成图像
训练完成后,通过逆向过程从噪声生成图像
- 从标准正态分布中采样纯噪声图像
循环进行以下步骤: - 使用训练好的网络
预测当前噪声水平下的噪声 - 计算去噪后的样本
: 其中, 通常设置为常数,例如 或
- 使用训练好的网络
- 最终得到生成的图像