WordScore 论文解读
WorldScore: A Unified Evaluation Benchmark for World Generation
Overview

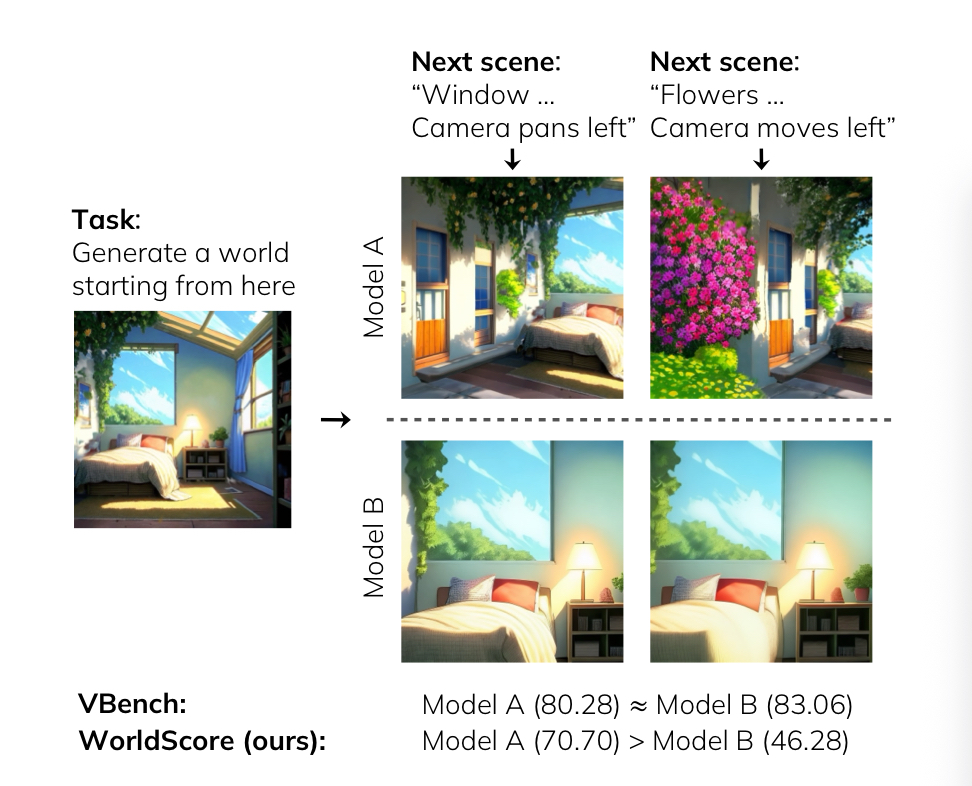
(1)统一性:将世界生成任务归纳拆解成了相机位姿变化下的下一场景生成任务,由此将3d生成,4d生成,视频生成等等世界生成方法统一化了
(2)测试维度:
可控性(controllability)
质量(quality)
动态性(dynamics)
(3)大规模,多样的测试示例:3,000 个高质量的测试示例;涵盖了各种世界,包括静态和动态、室内和室外、照片写实和风格化景
挑战
视频生成、3D 场景生成和 4D 场景生成初是为特定任务设计,虽然具备作为“世界生成系统”的潜力,但是在世界生成概念扩展的今天,难以适应既能够无缝集成多个不同场景(综合性),又能够具有详细空间布局控制(控制性)的任务需求。
解决这个问题,首先需要的就是一个benchmark!
现有benchmark的缺陷
视频生成方向
评估仅限于单个场景,无法衡量模型在生成多场景、具有复杂空间关系的“世界”时的能力
3d,4d场景生成方向
评估基准缺少关键组件(如摄像机规格和参考图像)。这使得这些基准与许多先进的 3D/4D 场景生成方法不兼容
WorldScore Benchmark
核心:将世界生成任务分解为一系列下一场景生成任务
统一性
每一个step被描述为
为了不同方法之间的统一:
为每一个
step中的current scene提供了image prompt和text prompt为每一个
step中的layout提供了camera matrices和textual description
无论输入是什么,不同方法之间的输出是统一的 i.e. 渲染或者生成的video
衡量标准
可控性(controllability):衡量生成的世界对控制输入的依从性
质量(quality):衡量逼真度和一致性
动态性(dynamics):衡量生成的世界表现出准确和稳定运动的程度
三大衡量标准里面所有指标加起来共十个metrics
主要贡献
(1)提出了第一个世界生成基准WorldScore,允许对包括各类模型在内的各种方法进行统一评估
(2)提供了一个高质量、多样化的数据集,涵盖了具有多种视觉风格的静态和动态场景
(3)引入了 WorldScore 指标,它包括可控性、质量和动态性

(4)在17个开源模型和2个闭源模型上评估,指导世界模型的研究,提出该研究领域的挑战

WorldScore Benchmark

整体概述
包括三个部分:
- 标准化的世界规范
- 精心策划的数据集
- 多方面的指标
世界规范
世界规范的定义
世界生成任务被分解为一系列下一场景生成任务,其中每个步骤由三元组
: 当前场景 :当前场景的图像 :当前场景的文本提示
表示下一场景的文本提示 :布局 :每一个位置相机的相机矩阵集合( 表示一个相机矩阵) :相机运动的文本提示
然后,世界生成模型被指示生成一个视频:
模型特定的预处理
评估模型涵盖3D场景生成、4D场景生成和视频(I2V,T2V)生成,每种模型都有不同的输入形式需求
为了适配这些不同的输入形式,
具体来说,
对参考图像
会被居中裁剪并调整大小,以匹配每个模型所需的分辨率
既作为视觉风格参考,也作为I2V模型所需的输入
因为T2V模型被视为忽略图像信号的I2V模型,所以T2V不接收
对布局
对于接受显式相机控制信号的模型,
会将对齐变换后的相机位姿 提供给那些模型,以保证在不同相机类型之间对齐, 对于不支持显式相机控制的模型,只提供文本描述
对于下一场景的文本提示
对于3D/4D模型,由于它们都接受相机矩阵作为输入,
不会对 做任何改动 对于3D/4D模型外不接受相机矩阵输入的视频模型,
会在 中加入相机运动相关的描述
两种任务———静态和动态世界
动态性与可控性和质量方面的性质不同,不适合作为一种metrcis进行评估
所以从任务上对于动态和静态进行区分:
静态世界生成:指示模型生成可变长度的场景序列。此时,
描述了新的场景内容, 描述了大的相机移动 动态世界生成:指示模型生成场景内运动以进行动态性评估。此时,
描述了与 相同的场景内容,但带有动态变化(e.g. animal moving)。 明确指定了一个固定的相机位置,没有任何相机移动
数据集策划
静态世界生成
过程1:逼真风格场景生成
过程2:以逼真风格场景生成为基础,生成风格化场景
 (1)定义了10个场景类别,5种室内场景和5种室外场景
(1)定义了10个场景类别,5种室内场景和5种室外场景
(2)从开源场景数据集和在线来源unsplash中获取图像
数据集如下:

(3)因为上述数据集存在信息冗余,视角异常,拍摄角度过窄等问题,对图像应用过滤策略,以确保高质量和高多样性,产生了5000张逼真风格(Photorealistic)的图像
视觉质量:
CLIP-IQA和CLIP Aesthetic过滤视觉质量视角问题:利用
Perspective Fields建模图像局部视角属性,如yaw,pitch,FOV,剔除roll,pitch异常和FOV过窄的情况相似度:采用
CLIPSIM移除极端相似图像亮度:计算图像亮度,过滤亮度低于阈值的图像
最后进行人工筛选
下图是图示筛选的过程:

(4)用VLM(GPT-4o),为这些图像生成字幕
(5)保留每个类别中前100张最高质量的图像,从而得到1000张图像

(6)为了保证风格的多样性,为每个逼真风格示例创建了一个Stylized副本。对于每个示例,从一组风格候选集

(7)利用闭源文生图api来生成风格化图像
最终的十类场景如下图所示,每一个场景上面是逼真风格,下面左侧是风格化结果,下面右侧是可选风格:

动态世界生成
(1)定义了 5
种运动类型,从unsplash手动为每种类型挑选了100张图像
(2)遵循与静态世界生成中(4)(5)(6)过程相近的方式创建了文本提示和风格化副本,最终得到1000个示例
(3)为每一张示例生成了一张Mask Image来指示运动应当在哪里发生
展示如下:

- 小世界(Small World),
只包含一个新场景 - 大世界(Large World),
包含三个新场景,共四个
文章指示LLM生成与所有当前场景文本提示
对于一个小世界: LLM 接受输入任务规范
, 以及对于过去和当前场景描述的prompt集合 对于包含四个场景的大世界,重复上述过程三次,因此包含三个独立的下一场景提示
具体而言,对于静态场景生成:

生成的

"Entities"是metric部分在计算可控性(controllability)时需要进行检测的对象
对于动态场景生成:

生成的

"Objects"是用于为运动对象提供mask,从而在metric部分中计算运动精度
对于相机运动,根据电影行业的启发,文章准备了一个涵盖8种相机运动的集合

这种设计两个好处:
涵盖了所有空间方向
text2video模型大多在包含这种运动描述的电影切片上训练过,所以这种标注
有利于text2video进行训练
8种运动的分类:
- 场景内运动,e.g., push in
- 场景间过渡, e.g., pull out
特别地,对于静态场景生成,文章随机为下一场景生成任务分配一个布局

WorldScore Metric
WorldScore包括两个集合:
- WorldScore-Static,仅衡量静态世界生成能力,包括可控性(controllability)和质量(quality)
- WorldScore-Dynamic,除了静态世界外还衡量动态世界生成能力,包括可控性(controllability),质量(quality)和动态性(dynamics)

可控性(controllability)
相机可控性(Camera controllability)
为了评估模型生成内容对布局
使用DROID-SLAM来估计每一帧的相机位姿
生成视频

引入
单目视觉无法判断物体的真实大小或距离,估计的
对于单目SLAM,只能估计出up-to-scale的平移向量
因此引入
物体可控性(Object controllability)
评估下一场景提示
从Grounding dino在场景中进行检测并且计算与物体描述的匹配成功率

内容对齐(Content alignment)
利用CLIPScore评估生成的场景与整个文本

质量(quality)
3D 一致性(3D consistency)
应用范围:静态世界视频(static world videos)
侧重点:(1)场景的几何形状在帧之间如何保持稳定 (2)视觉纹理的轻微变化可以容忍
使用DROID-SLAM来估计每帧的像素级深度,好处是使用DBA(密集的Bundle Adjustment)稠密重建,利用好图像中每一个像素的信息,更好捕捉全场景一致性
然后计算连续帧中一对共视像素之间的重投影误差
意义:如果3d consistency良好,那么3d reconstruction之后的三维结构和相机位姿的自洽性良好,那么重投影误差应该小
对比示例图如下:

光度一致性(Photometric consistency)
侧重点: 外观(纹理) 的稳定性
现有问题:(1)视频生成模型在保持纹理一致性方面存在困难
(2)现有指标,如以CLIP和DINO为基础的,难以衡量细粒度变化
为了检测光度伪影(photometric artifiacts),评估了连续帧之间的光流并计算平均端点误差(Average End-Point Error AEPE)

具体地,给定两帧相邻帧
先估计相邻帧之间的光流场
先用从
再用从
理想情况下,如果物体光度一致,被跟踪的点会回到原始位置,即
总体度量通过对所有生成视频的所有相邻帧对的
较高的该指标表明光度不一致更严重,会反映出例外观变化、纹理闪烁或物体消失等异常
风格一致性(Style consistency)
计算单个下一场景生成任务的第一帧和最后一帧的Gram矩阵之间的差异来评估
通过逐层的CNN对每一帧进行特征提取:
在第
Gram 矩阵
衡量的是第
从视觉意义上讲,这个矩阵保留了某张图像“纹理/局部特征与色彩共现的信息,并丢弃了像素的全局几何排列,而正与审美角度的“风格“相符合
使用Frobenius范数来衡量两个Gram矩阵之间的差异

主观(人类感知)质量(Subjective quality)

背景:现存许多训练好的图像质量评价指标模型,如CLIP-Aesthetic,QAlign-Aesthetic,MUSIQ,CLIP-IQA等等
目标:在以上的指标中进行组合,选取出最为贴近人类感知偏好的组合
方法:人工实验
- 选择200个实验的人,给定一个视频对(A,
B),问问题
which video has higher quality,并强制要求二选一 - 选 A 的比例为
, 选 B 的比例为 - 用待实验的metric
对(A, B)进行评判,若给A打分高 ,那么m在(A, B)上的agreement score就是 ;若给B打分高 ,那么m在(A, B)上的agreement score就是 ; 若是 ,m在(A, B)上的agreement score就是 , 的最终得分取在所有视频上的平均分 - 问题没有问很细致,只问到
quality的原因是:过于细致的问题,实验者很难做出果断的回答
结论:CLIP-IQA+ and CLIP Aesthetic最高,upper_bound是该指标若每次都选比例更高一方所能达到的上限

动态性(Dynamics)
运动准确性(Motion Accuracy)
评估:下一场景提示
方法:
SEA-RAFT估计得到
用SAM2去跟踪这些动态物体掩码
公式含义:取动态区域的最明显运动减去静态区域的最明显运动,该数值越大,说明运动集中在它该发生的区域
最终对视频中所有连续帧对计算

运动幅度(Motion Magnitude)
评估:世界生成模型生成大幅度运动的能力
动机:生成细微运动缺乏趣味性
方法:
SEA-RAFT估计得到
最终对视频中所有连续帧对计算

运动平滑度(Motion Smoothness)
评估:生成视频
动机:时间抖动(temporal jittering)是动态世界生成问题中的常见失效模式
方法:
给定一个生成视频,其帧序列为
,将奇数索引帧 删除,得到一个帧率较低的视频;然后使用视频帧插值模型 Vfimamba推断出这些被删除的帧,插值后的帧是平滑帧,作为插值前的帧的参考计算重建帧与原始被删除帧之间的均方误差(MSE)、结构相似性(SSIM)和LPIPS
计算并采用下面的归一化方法归一化每个指标后,取平均值,得到最终的指标

归一化方法
其中:
10个metric之间的统一
在计算出各项独立的指标后,应用下文的经验限度和上文的归一化方法确保最终分数落在0-1,然后将其乘以 100 接着,计算controllability和quality两个维度得分的算术平均值,得到WorldScore-Static 此外,将三个动态维度的得分纳入,从而得到WorldScore-Dynamic 对于不支持动态任务的 3D 场景生成模型,将每个动态指标的得分设为0
经验限度
相机可控性
越小越好
下限:0 (无偏差)
上限:在相机一直不动的情况下计算出来的偏差就是上限
物体可控性
越大越好
由于该指标使用物体检测率,上限1,下限0
3D一致性、风格一致性和光度一致性
越小越好
下限:0 (完全一致)
上限:完全随机图像对,使用Vfimamba插值生成视频,该视频的评分就是上限
运动平滑度
越小越好
下限:0 (完全平滑)
上限:选取一些视频,删除奇数帧,用双线性插值重建,代表经验最差
内容对齐、主观质量、运动准确度和运动幅度
越大越好
使用z-score rescaling,手动将性能分落在25-75之间
启发

3D 模型在静态世界生成方面表现出色
视频模型缺乏相机可控性
最佳开源视频模型与闭源视频模型一样好
运动平滑度和运动幅度之间存在权衡
更大的运动不一定意味着更准确的运动定位
视频模型在长序列生成和户外场景中表现较弱
T2V 模型比 I2V 模型更容易操纵